Method
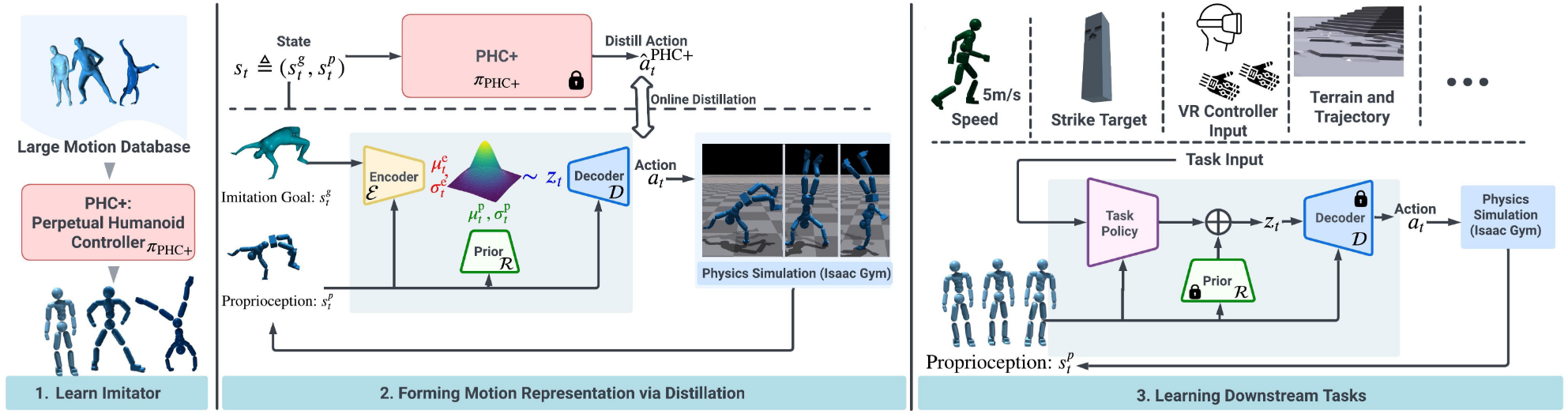
1. Motion Imitator
即预训练“运动模仿器”,目标是训练一个能完美复刻人类动作的网络。
- 输入:机器人当前的状态 $s$(各个关节的角度、速度等),以及一段来自 AMASS 数据集的未来参考动作序列 $q^*$(如接下来 0.5s 内真人动捕的姿态)
- 输出:底层物理控制指令 $a$(具体到每个电机的目标角度或扭矩,论文中用的是 PD 控制器的目标位置)
- 训练:使用强化学习的 PPO 算法在物理仿真环境 Isaac Gym 中进行训练。如果机器人的关节角度、根节点(骨盆)位置、末端执行器(手脚)的位置与传入的参考动作 $q^*$ 高度一致,就会得到高分;如果摔倒或动作走形,则扣分
- 结果:得到一个模仿器$\pi_{imi}(a|s, q^{*})$,只要给它看一段人类怎么动,它就能在物理引擎中分毫不差地把相应的受力动作做出来
2. Skill Distillation
只有一个模仿器$\pi$是无法在下游任务中直接使用的,因为我们无法知道未来参考动作 $q^*$是什么,因此先需要通过条件变分自编码器(cVAE)进行“技能蒸馏”。
2.1 Encoder
编码器$E(z|s, q^)$会观察当前状态$s$和未来参考动作$q^$,接着将$q^$压缩成一个仅有32维的低维隐变量分布$z$,可以将$z$理解为对$q^$的高度抽象概括,比如“左腿向前迈一小步”。
2.2 Decoder
解码器$D(a|s, z)$看不到未来的参考动作$q^$,只能接收当前状态$s$和编码器将$q^$压缩后的隐变量$z$,目标是输出物理动作$a$。
2.3 Loss
- 动作重建损失:解码器输出的动作$a$,必须和模仿器$\pi$面对相同情况时输出的动作完全一致
最终,我们扔掉模仿器和编码器,在面对新任务时,高层策略只需向解码器输入隐变量$z$。
3. Proprioception-conditioned Prior
在基于物理的人形机器人,接下来的动作(序列)是高度依赖当前状态的。比如机器人此时正躺在地上,那么接下来就不可能立刻做出“跨栏”的动作。
如果让解码器强行执行,机器人很可能会违反物理规律。也就是说,输入给解码器$D$的隐变量$z$,必须受限于机器人当前的物理姿态。
因此该论文引入了本体感受,即状态向量$s$,包括:
- 所有关节的当前角度(Pose)
- 所有关节的角速度和线速度(Velocities)
- 根节点(骨盆)的高度和旋转状态
并引入了先验网络 $p_\theta(z|s)$,和编解码器联合训练:
- 先验网络看不到未来参考动作序列$p^*$,只能根据当前本体感受状态$s$盲猜$z$
- 损失函数:
- 让先验分布尽量向标准正态分布$\mathcal{N}(0, I)$靠拢
- 让编码器的分布和先验网络的分布计算 KL 散度:$D{KL}(q\phi(z|s, q^*) \parallel p_\theta(z|s))$
这样先验网络就能学习到一个规律:在当前姿态$s$下,人类通常会采取哪些合理的下一步动作?
在先验网络训练完成后,我们可以将机器人当前状态$s$输入先验网络,其会输出一个高斯分布$\mathcal{N}(\mu_s, \sigma_s)$,这个分布框定了当前姿态下所有合理的动作指令合集。接着从这个分布中随机采样(输入高斯噪声)得到$z$,输入给解码器去执行,就能得到合理的随机动作生成。
4. High-Level Policy
利用分层强化学习,在进行下游的具体任务(如走迷宫、被击打后恢复平衡)时,之前训练的解码器和先验网络的参数不再更新,而是作为机器人的“基础运动反射神经”,然后引入高层策略网络$\pi_{high}$
- 输入:机器人的当前状态$s$(姿态、速度等),和任务特定的观察信息$o_{task}$
- 输出:直接输出 32 维的高级指令$z$
- 训练:$\pi{high}$不是直接输出$z$,而是先验网络先根据$s$输出$z$可能的分布,$\pi{high}$再输出相对于该先验分布的一个偏移分布,最后再在偏移分布中采样输出$z$。并在奖励函数中加上了先验分布和偏移分布的 KL 散度惩罚。
Conclusion
Advantage
- 高层训练时接近零摔跤的探索:这是因为高层策略输出的$z$(或$z$的分布)被先验分布束缚在了安全区域内,这让机器人专注于如何完成任务而不是如何做出合理的动作
- 极简的奖励函数设计:传统的 RL 为了让机器人的动作像人,需要手工设计极其复杂的奖励函数。而本论文由于先验网络和解码器的存在,高层策略只需要注重于任务相关的奖励函数
- 频率解耦:高层策略可以每隔一段时间(如10Hz)输出一个高层次意图$z$,底层解码器可以高频率在物理引擎中计算关节力矩。这样能节省计算资源,并拉长了模型能够规划的时间视野。