Introduction
Background
- 传统 Diffusion 模型生成质量高,但通常是“非增量”的,即生成视频之前必须预先设定好帧数
- AR / GPT 类模型像语言模型一样预测下一个 Token,可以无限生成。 但它们通常依赖离散化的非因果 Token(如 VQ-VAE 的量化词表),这会导致严重的信息丢失,在生成长序列时产生累计误差,导致动作失真或变形; 并且由于非因果标记化架构会阻止在整个序列生成完成前进行部分标记解码,导致难以实现在线响应
- DART 虽然可以实现实时运动生成,但它依赖固定窗口的局部运动基元,本质上限制了它们对可变长度历史上下文进行建模以及对不断演变的文本输入动态对齐的能力
Related Work
- T2M:
- 运动压缩:其他人使用 VQ-VAE、RVQVAE 等将原始运动序列编码到离散的潜在空间,然后使用 GPT、Diffusion 等进行运动生成。但现在方法都要对整个运动序列进行编码和解码,不适合流式生成。
Contribution
Motion-Streamer 实现了可在线响应的流式生成,可以像人类听指令做动作一样,一边接收不断输入的文本,一边实时、平滑地生成连贯的动作序列。只要有持续的文本输入,就能一直生成下去。 除此之外,也适用于动态动作组合,即后续动作可以通过改变文本条件来重新生成,同时保留最初生成的前缀动作。
- 输入:指令文本 + (历史运动序列)
- 输出:指令对应运动序列
Method
0. Formulation
- ${P{i}}{i=1}^{M} \to {x{j}}{j=1}^{N}$ $P_i$是第$i$个文本描述,$x_j$是第$j$帧的姿势
- $x = { \dot{r}^x, \dot{r}^z, \dot{r}^a, j^p, j^v, j^r } \in R^{272}$ 直接使用基于 SMPL 的 6D 旋转作为关节旋转以便转换为 SMPL 身体参数
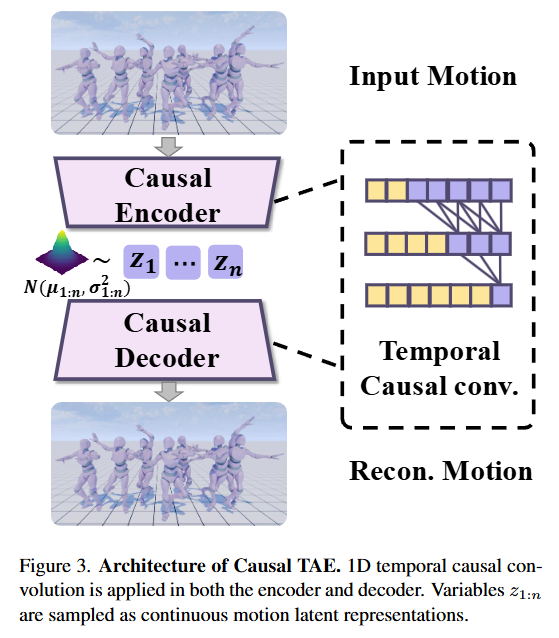
1. Casual TAE
因果性
通过 1D 因果卷积,确保模型在编码和解码当前帧时,不会“偷看”未来帧,这种严格的时间因果依赖是实现在线实时解码的基础。
$pad = (k_t - 1) * d_t + (1 - s_t)$
通过只在序列左侧填充 padding,切断了信息向后流动,即计算第 $t$帧的特征不会用到第 $t$ 帧后的信息。
连续性
动作本质上是连续的物理量,作者坚持用连续的潜变量而不是离散 Token,这能减少量化带来的信息损失,缓解误差累积。
$X = {x_1, x_2, …, x_N} \qquad x_t \in R^D(D = 272)$
编码器处理$X$后,先输出服从高斯分布的参数集合${ \mu{1:N/l}, \sigma{1:N/l}^2 }$, 再通过重参数化技巧、采样得到连续的动作潜变量$Z = {z_1, z2, … , Z{N/l}}$。 其中$z_i \in R^{d_c}$,潜空间维度被压缩到了$d_c=16$ ,并且在时间维度上进行了下采样$l=4$ 。
训练
$\mathcal{L} = \mathcal{L}{recon} + D{KL}(q(z|x)||p(z)) + \lambda\mathcal{L}_{root}$
- $\mathcal{L}_{recon}$:原始动作与重构动作之间的差异,并除以了 MSE 以对大尺度的误差更鲁棒
- $D_{KL}$:将编码器输出的连续潜空间分布拉向标准正态分布,使得潜空间更加平滑和连续
- ${L}{root}$:根节点的全局平移和旋转损失$(D{root}=8)$
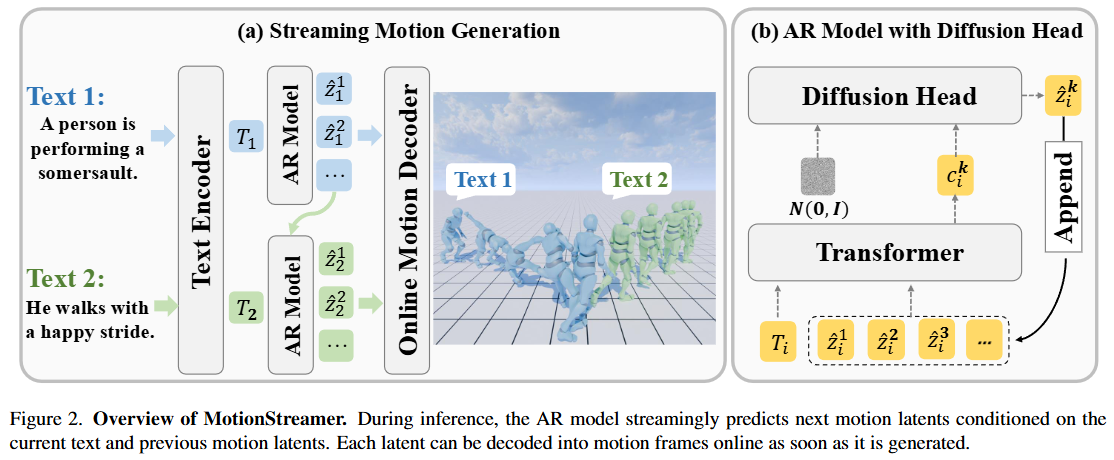
2. Diffusion-based AR Model
- 特征融合:将输入一段新文本时,预训练模型 T5-XXL 先提取文本特征,并将其与历史动作特征拼接
- AR 预测:将拼接的特征输入一个基于 Transformer 的自回归模型,输出一个条件特征
- Diffusion 生成:将条件特征输入一个轻量级的 Diffusion Head,预测连续动作的下一帧潜变量
训练
$S_i = [T_i, C_i, Z_i]\qquad (T_i \in R^{1d_t}, C_i \in R^{k, d_c}, Z_i \in R^{n d_c})$
- $T_i$:预训练模型提取的当前文本特征
- $C_i$:由 Casual TAE 编码的上一段历史动作潜变量,如果没有则设为 NULL
- $Zi$:由 Causal TAE 编码的当前真实动作潜变量(模型要学习去生成的目标),并且末尾人为的添加了一个“不可能的姿势”$z{imp}$
序列$S_i$首先由 Transformer 处理,并应用因果掩码确保时间因果性,得到(训练时是并行的)中间潜在变量$c_i^1, …, c_i^n$(数量和$Z_i$相同)。接着将这些中间特征作为条件输入一个非常小的扩散头(MLP),预测出最终的连续动作潜变量$\hat{Z}_i$。
$\mathcal{L} = \mathbb{E}{\epsilon, t} [||\epsilon - \epsilon\theta(Z_t | t, C_i, T_i)||^2]$
- $t$:$1-T$,加噪步数
- $Z_t$:将真实动作特征$Z_i$加入随机噪声$\epsilon$污染$t$步之后得到的加噪特征($Z_i$ ? $z_i$)
- $\epsilon_\theta$:扩散头通过加噪特征$Z_i$,在加噪步数$t$、$C_i$和$T_i$的条件下预测出来的随机噪声
PS:预测噪声和直接预测原始数据在数学期望上是等价的,并且预测噪声能让训练过程更稳定,且最终生成的数据更具有多样性,其本质是在学习数据分布的梯度
推理
首先将第一个文本嵌入$T_1$输入 AR 生成器,以生成第一个预测的运动潜在序列$\hat{Z}_1=\hat{z}_1, …, \hat{z}_n$(具体来说,先生成一个完全随机的纯噪声向量$Z_T \sim \mathcal{N}(0, I)$,接着扩散头结合条件$c$逐步预测并去除当前步的噪声$\epsilon$,最终得到$\hat{Z}$),接着立即交给 TAE 在线解码,输出最终的运动帧。如果当前预测的运动潜在变量$zi$与参考结束潜在变量$z{imp}$之间的距离低于阈值,当前运动序列的生成就会停止,此时$n=i$。(先前的方法应用二元分类器来预测是否停止生成,但无法学习到正确的停止条件)
接着将下一个文本嵌入$T_2$替换掉$T_1$,已生成的运动潜在序列$\hat{Z}_1$被附加到$T_2$末尾,作为下一个自回归步骤输入的上下文潜在变量。预测出$\hat{Z}_2$后,用$T_3$替换掉$T_2$,$\hat{Z}_2$替换掉$\hat{Z}_1$,再进行下一个序列的预测,以此重复……
3. Two-Forward Training
自回归模型在训练时总是看真实的上一帧,但推理时只能看自己生成的上一帧,一旦前期生成错了一点,后面的预测仍会出现累计误差
- 第一次前向传播:完全使用真实的动作数据作为输入,生成初步的预测潜变量
- 第二次混合前向传播:使用余弦调度器,将输入中部分真实的潜变量,替换为第一次前向传播中预测出来的结果,再进行一次生成计算
Experiment
Baseline
数据集
- HumanML3D
- BABEL
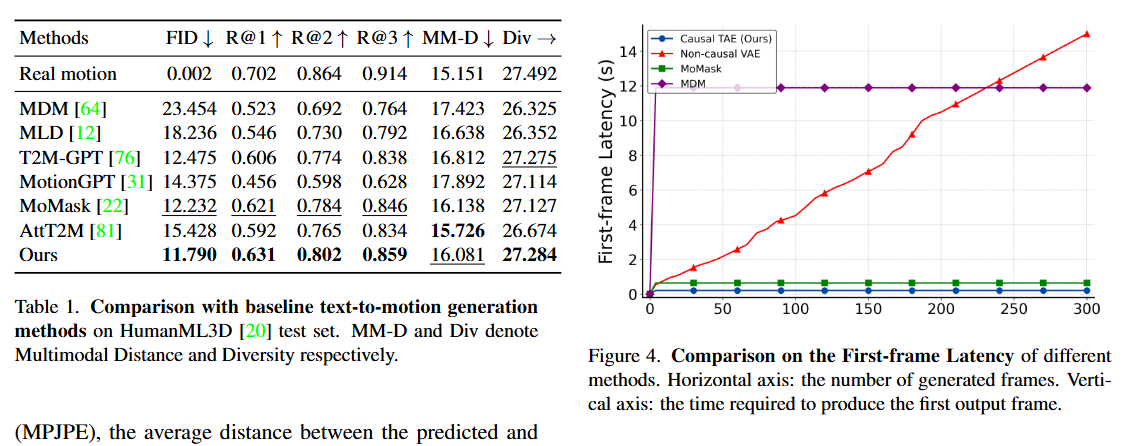
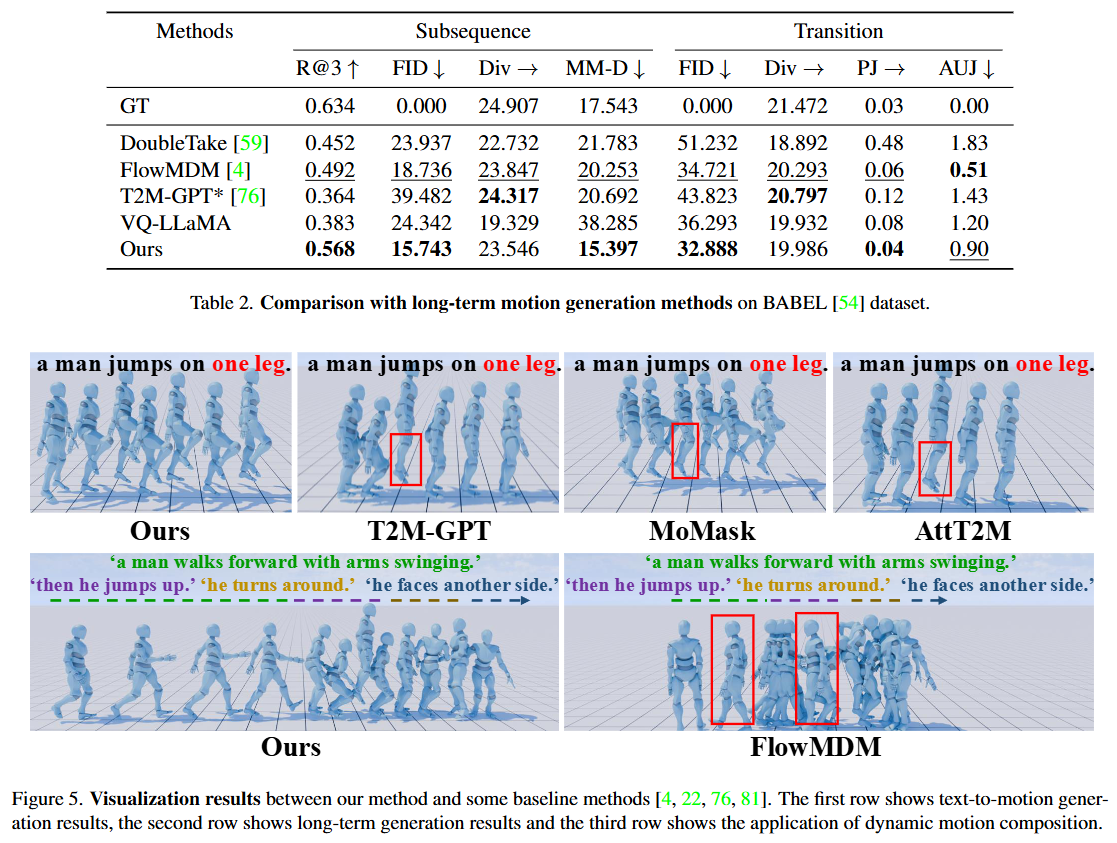
Ablation
