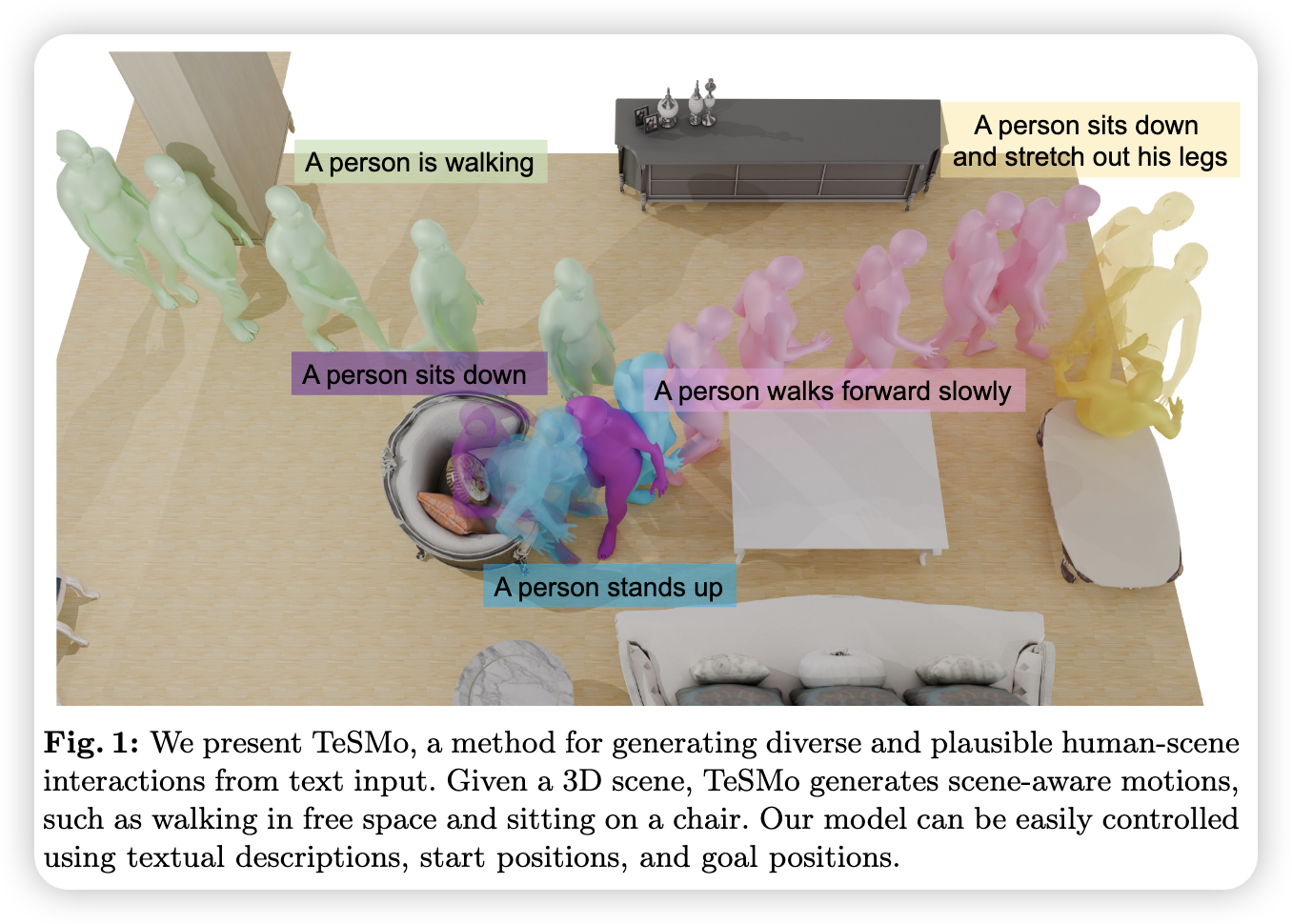
Introduction
Background
- 同时包含运动、文本描述和交互场景的数据集数量有限,以往的T2M方法仅关注孤立的人物动作而未考虑环境因素
Related Work
- 先预测根路径,再基于场景和预测路径生成全身运动
- 在3D场景中往往无法避开障碍物,需要借助$A^*$进行无碰撞路径规划
- 创建合成数据以改善数据问题,但真实度受生成方法限制
- 强化学习无需配对训练数据,但仍依赖$A^*$算法,且受限目标姿态生成的准确性?
- 基于扩散模型的研究聚焦于人类操控动态物体,而非完整场景中的交互行为
Contribution
- 在预训练的T2M扩散模型基础上,通过一个以场景信息为输入的增强型场景感知组件对其微调,实现场景感知的文本条件运动生成
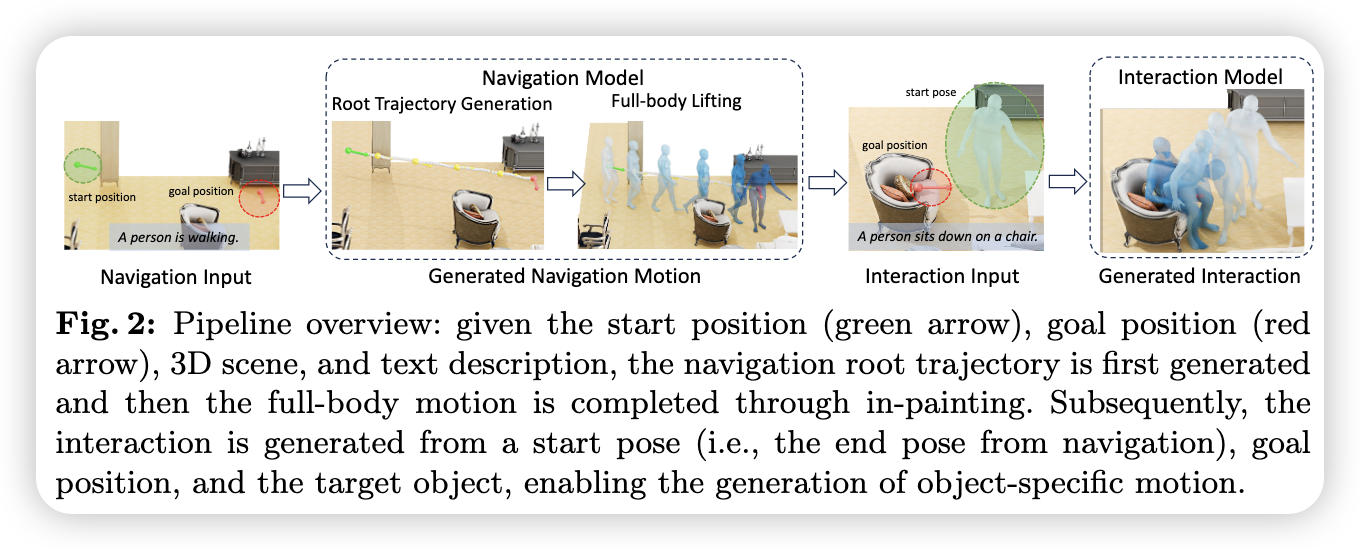
- TeSMo:将场景交互运动分解为导航和交互模块两个模块
- 数据增强:将带有文本标注的导航和交互运动数据真实地放置在场景中,以支持场景感知微调
Method
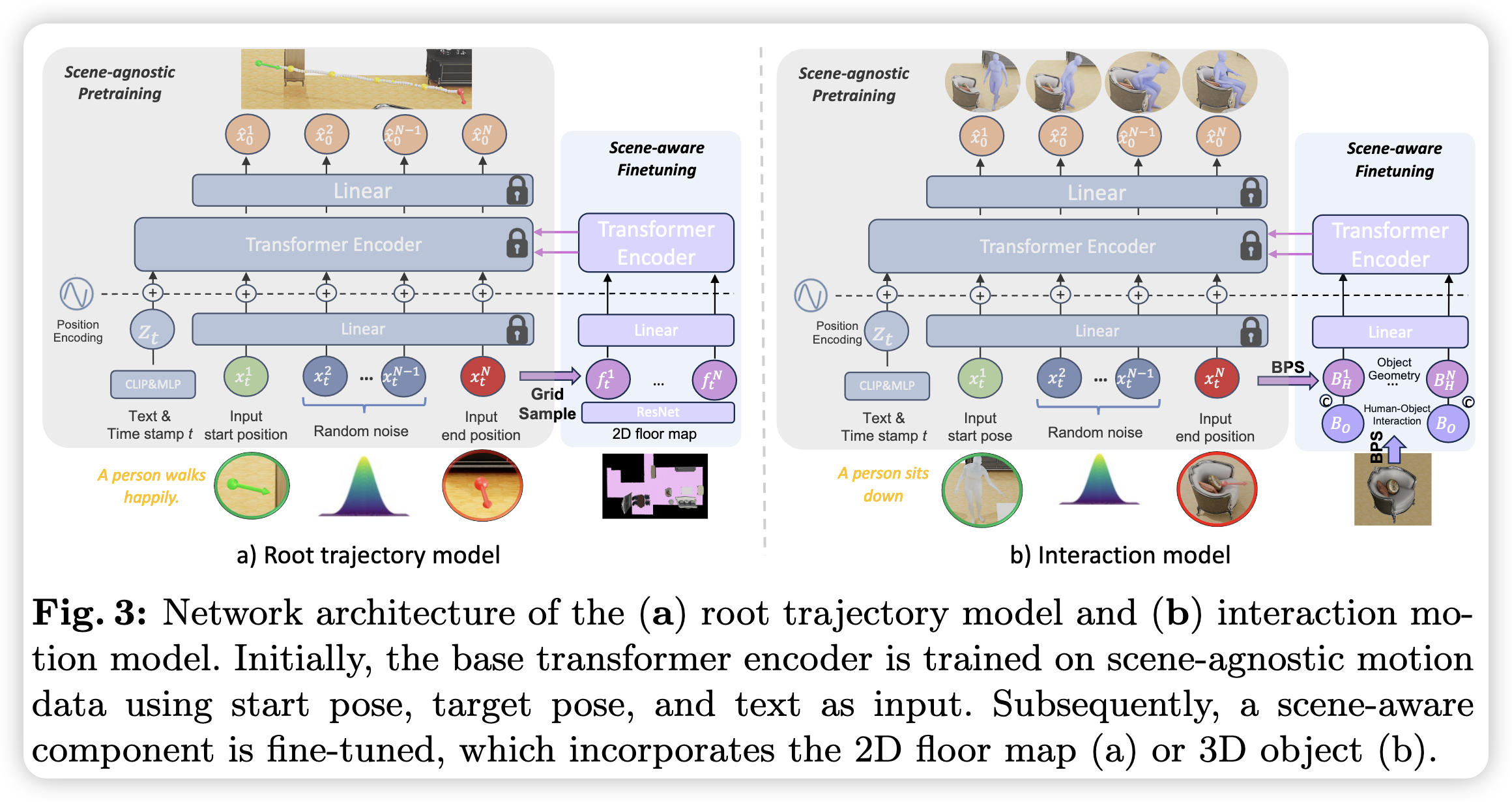
导航和交互都预先训练一个与场景无关的运动扩散模型,以从文本提示中生成逼真的运动,然后通过ControlNet微调一个以场景信息为输入的增强分支
1. 数据增强
- 将无场景的人体移动数据集HumanML3D数据集融合到了多样的3D室内环境数据集3D-Front,每一个序列放置在不同的场景里,且位置和朝向随机,同时序列和场景都做了镜像
- 提取(拆分)SAMP数据集中包含特定交互动作的子序列,并标注详细的文本描述;同时从3D-FRONT中随机挑选物体,去匹配原始 SAMP序列中人体姿势的接触顶点,并利用了特定的接触和碰撞损失技术来确保人体与物体接触时的物理合理性;同样做了镜像
2. 导航运动生成
2.1 根轨迹生成
目标是用户通过文本控制角色的真实运动,抵达目标物体附近的目标位置
设计了一种分层方法:首先利用扩散模型生成密集的根轨迹,随后使用修复模型为预测出的轨迹生成全身运动,其中修复模型支持多样化的文本控制
输入:
- 文本提示
- 起始和目标位姿的位置与方向
输出:
- 导航路线的根关节路径
位姿$\mathrm{x}^n=[x,y,z,\cos\theta,\sin\theta]_n$,$\theta$为骨盆旋转角度,均采用绝对坐标表示,便于通过目标位姿对模型输出约束
在加噪或去噪过程中,运动序列的第一帧(即起始位姿)和最后一帧(即目标位姿)始终保持不变,此通过掩码$m=[1, 0, …, 0, 1]$实现,将掩码后的数据和掩码拼接后作为模型输入
测试指标使用预测的目标位姿和实际位姿的误差
2.2 融入场景表征
冻结训练的基础扩散模型,使用Transfomer作为控制分支进行微调
用Resnet-18将3D场景投影至鸟瞰视角的可行走区域的每个网格进行编码,在去噪时查询每帧2D投影后的位置以获取对应网格的特征$f$,将文本提示词、带噪运动序列和特征序列作为Transformer的输入
测试指标使用SDF碰撞引导,即不在可通行区域内的姿态会收到惩罚。利用惩罚产生的梯度,将预测的轨迹“推回”到安全的可行走区域
2.3 轨迹控制
在去噪的每一个时间步$t$,将模型预测的轨迹和用户输入的轨迹$p \in R^{N*2}$按比例$s$进行插值融合,用融合的轨迹覆盖预测轨迹再继续去噪,这样角色能大致按照用户画的路线走
2.4 姿态补全
利用现有的T2M修复方法PriorMDM,输入是密集的二维根轨迹
3. 交互运动生成
角色抵达目标物体附近后,需执行期望的交互动作,由于交互过程存在精细的关联关系,需要训练另一方面扩散模型直接生成全身动作
3.1 交互姿态生成
姿态$x^{n}=[x, y, z, \sin \theta, \cos \theta , \dot{r}^{a} , \dot{r}^{x} , \dot{r}^{z} , r^{y}, j^p, j^v, j^r, c^f]_n \in R^{268}$
输入:
- 文本提示此
- 初始全身姿态(即导航的最终姿态)
- 目标骨盆位置和姿态
目标骨盆姿态可由启发式方法算出也可由用户提供,输入同样采用导航阶段的掩码处理
测试阶段也采用相同的目标达成引导来提高姿态命中率
3.2 物体表征
为交互扩散模型添加一个新的物体感知Transformer编码器并进行微调
首先在目标物体中心定义一个半径为$1.0$的虚拟球体,然后在球体内部随机洒下1024个点构成基点集(BFS),通过计算基点集到物体表面的最短距离提取物体几何特征$B_O \in R^{1024}$
接着在每个去噪时刻$t$的每个序列帧$x_t^n$,计算$B_O \in R^{1024}$到人体任何关节的最小距离为人-物空间关系$B^n$
然后将每个时间步的表示拼接为$[x_t^n; B^n; B_O]$输入至MLP融合,作为场景感知的输入。
训练时同样采用类似的碰撞损失
Experiment
Baseline
测试集
Loco-3DFRONT
评估指标
- 根轨迹:目标到达准确率;碰撞率
- 全身姿态:FID;R-Precision;多样性;脚部滑动率
- 交互:位置、朝向、高度误差;动作与物体的平均穿透值(率);用户对比
结论
- 生成的运动效果可以最先进的扩散模型相媲美,且相比现有研究,进一步提升了交互动作的合理性与真实感
- 预训练后微调的方式,会优于将完整的双分支架构从零开始训练
- 有时会导致生成的骨盆轨迹与修复后的全身姿态出现脱节
- 当前基于二维平面图的方法限制了处理复杂交互场景的能力
Ablation
- 在我们模型的姿态补全方法中,PriorMDM的效果比OminiControl要好,主要是因为后者会覆盖生成的密集骨盆轨迹
- 导航阶段采用先生成根轨迹再补全全身姿态,比直接生成全身姿态更有效且更多样性