Introduction
Background
- 粗糙的小数据集无法捕捉运动细节与语义多样性, 即使是大规模数据集上训练的方法也难以泛化至复杂的文本指令,尤其是组合指令
- 现有运动表征无法兼顾局部关节精度和全局轨迹一致性,在大规模训练中会愈发严重
- 多动作生成和身体部位编辑依赖碎片化的流程,将分别生成的组件拼接而成,这表明其缺乏对统一运动语义的真正端到端理解。 最根本的是,现有方法从头训练运动模型,放弃了预训练多模态大语言模型中已编码的丰富动作语义与长程推理能力——这一局限性共同导致方法无法泛化至复杂的语言-运动依赖关系和细粒度要求
Related Work
- MDM、MLD 等方法主要依赖 CLIP 作为文本编码器,限制了其对复杂的运动特定语言和时间关系的理解能力
- 大多数方法均从头开始训练,放弃了预训练多模态大语言模型中已编码的丰富动作语义,因此无法在语言描述与运动表达之间建立真正的语义对应关系——尤其是在涉及多个动作、肢体细微差异或上下文相关行为的复杂场景
- 现有编辑方法仍与训练分布紧密耦合,在处理任意语义文本描述时泛化能力有限
- 仅含运动数据的数据集——> 运动捕捉数据集——>结构化的运动-文本配对数据集——>身体层级的标注——>运动关联多条文本描述——>视频恢复运动
Contribution
- MotionGB:一个包含1万小时高质量精细标注的运动语言数据集——提供了理解复杂运动模式所需的语义广度与质量,涵盖从简单动作到复杂的多部分序列,可支持生成和编辑两类任务
- 一种基于 SMPL-X 的可扩展运动标记化方法——该方法同时保留局部关节精度与全局轨迹一致性,在大规模训练下实现了最先进的运动保真度
- MotionMaster:一个用于文本引导运动生成与编辑的统一端到端框架——通过利用大规模运动数据对预训练的多模态大语言模型进行微调,并证明了该框架在各类文本-运动任务中具备出色的零样本泛化能力
Method
1. MotionGB
数据采集
MotionGB源自三个来源的 400 小时原始运动数据
- 高保真骨骼运动的运动捕捉数据集
- 通过 GVHMR 从视频中提取 SMPLX 运动数据
- 专属运动录制数据,捕捉了现有数据中代表性不足、富有表现力且细腻的人类动作
多层次运动描述
- 首先提取逐帧运动报告,记录关节角度、肢体位置、躯干朝向和运动速度
- 将量化报告输入 Gemini,生成高层意图、整体动作、中间阶段以及细粒度细节四个语义层级的描述
数据集扩展
采用三种增强流水线,将数据量从 400h 扩充至 10000h,同时生成用于训练的运动编辑配对数据
- 时间组合:将 2-3 个动作序列拼接起来,并对描述进行语法修改,此外训练了一个动作补间模型生成 1s 过渡片段以确保过渡自然
- 身体部位拼接:融合不同身体部位的动作以产生同步动作
- 细粒度运动调整:应用 24 种参数化修改方式(关节变换、速度变化等),生成一段新的运动轨迹,并附带修改的精准描述
2. 运动标记化
FSQ
通过一维卷积编码器 $E$ 对 $T$ 帧的输入进行时间下采样:
$z = E(f) \in R^{T^{'} \times D}$,其中$f \in R^{T \times D}$,$D=85$;
并且对每个潜在元素都做了离散化:$\hat{z}{i,d}=round(z{i,d}\cdot L_d)/L_d$,
量化后的特征通过对称解码器上采样至原始时间分辨率;
相比于 VQ-VAE 主要有以下优点:
- 梯度更新的非凸性可能导致 VQ 的大部分向量永远不更新,而 FSQ 不用学习更新
- FSQ 前向传播只需要取整 round,而反向传播由于不可导,只需用直通估计器 STE 将梯度原样传回,训练稳定
- 相比 VQ,标记化的时间复杂度从$O(n)$ 降到了 $O(1)$
- VQ 码本中的索引是无序的,而 FSQ 的 token 是基于坐标系生成的,相邻的坐标在物理意义上代表着相近的动作
局部特征提取
给定一个运动序列,其中包含$t$个时刻$J$个关节的关节位置$J_t \in R^{J \times 3}$以及根方向$r_t$,提取$D=85$维的特征向量用于表示在局部坐标系中$t$到$t+1$时的运动变化:
- 偏航角
- 偏航角变化
- 所有关节的相对坐标
$f =[\triangle \thetat, flatten(p^{'}{t+1})] \in R^{85}$

这种局部化确保了相似的运动模式会生成相似的特征,无论在世界空间中的绝对位置如何
全局重建与损失函数
给定重构特征$\hat{f}_t =[\triangle \hat{\theta}t, flatten(\hat{p}^{'}{t+1})]$,迭代恢复全局运动

由于相对误差会随时间累计,所以直接监督全局联合位置和速度以防止漂移
逆运动学求解器(推理)
将生成的关键点轨迹转换为 SMPLX 参数本质上是约束不足的问题,误差会快速积累。
通过两阶段由粗到细的逆运动学解决这个问题:
- 通过人体姿态先验生成器 VPoser 先找出逼近当前关键点轨迹的人体姿态
- 再通过直接旋转关节角度微调姿态,使其精确贴近姿态
3. MotionMaster
统一运动-文本建模
使 Qwen2.5-VL 在共享嵌入空间中同时处理运动和文本 token:通过将原始码本中使用频率最低的文本 token 替换为 离散运动 token,做到在不扩大词汇表的同时将其整合到 MLLM 现有的词汇表中
在训练的微调阶段,冻结文本标记的嵌入层,仅对运动标记嵌入层和 Transformer 权重进行训练,采用因果注意力机制实现自回归生成:$P(mt|t{prompt}, m<t)$
使用 RoPE 为文本和运动模态使用独立的计数器:文本计数器按顺序跟踪所有文本,遇到动作开始标记SOM时暂停计数,此时运动计数器清0并开始计数,遇到动作结束标记EOM时文本再开始计数
语义平衡
确保模型在训练过程中对运动空间实现均匀覆盖:先通过计算语义密度再动态调整采样概率
Experiment
Baseline
数据集
MotionGB
评估指标
- 局部运动精度+局部关节位置误差
- 全局轨迹一致性
- 语义对齐(查询 Gemini)
- 对于生成任务:询问动作是否与文本匹配
- 对于编辑任务:将原始和编辑任务并排渲染,以10分制对其正确性和简洁性评分
- 物理合理性(查询 Gemini)
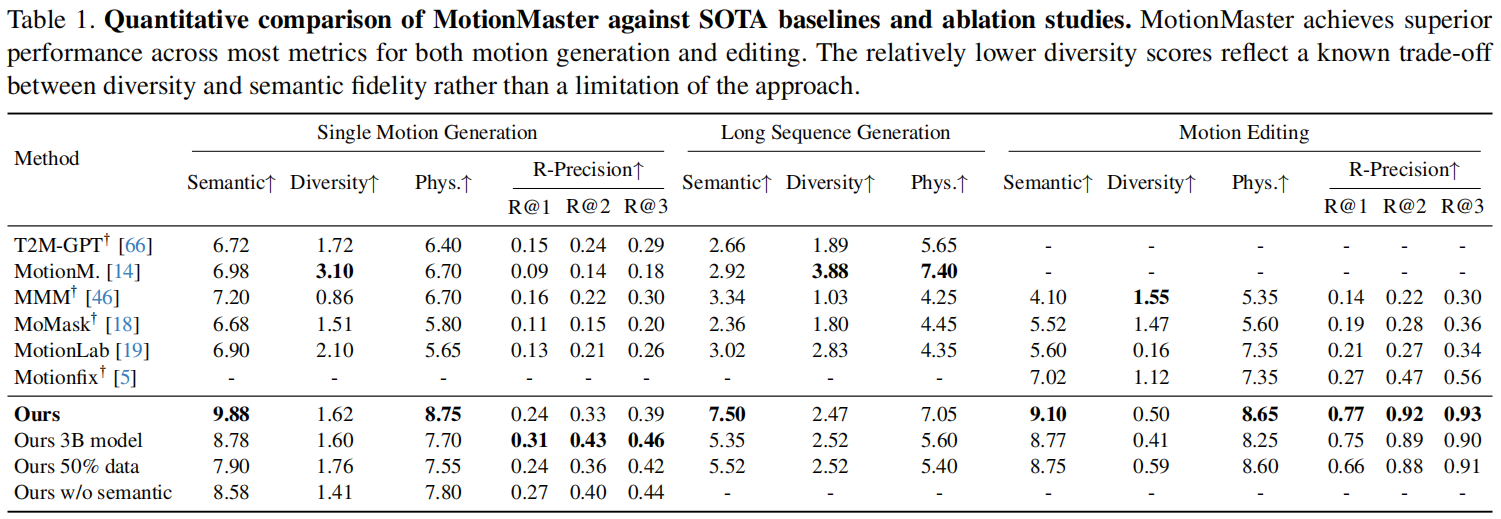

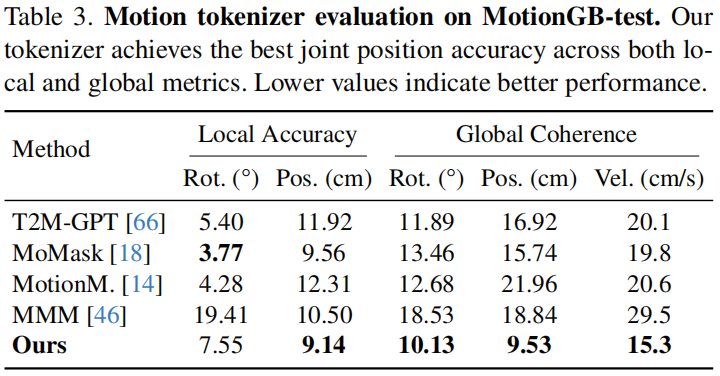
结论
- 旋转误差较大,可归因于各骨骼轴向的旋转未定义?
- 多样性分数较低,反映了与语义保真度之间的权衡
Ablation
- 数据集的规模、多样性及模型容量对运动生成能力至关重要
- 语义平衡能带来显著增益
- 生成和编辑任务进行联合训练更能提升训练质量,证明了二者的互补性