- https://sirui-xu.github.io/InterDreamer/
- NeurIPS 2024
- Cited by 63
- Sirui Xu† Ziyin Wang†
- University of Illinois Urbana-Champaign
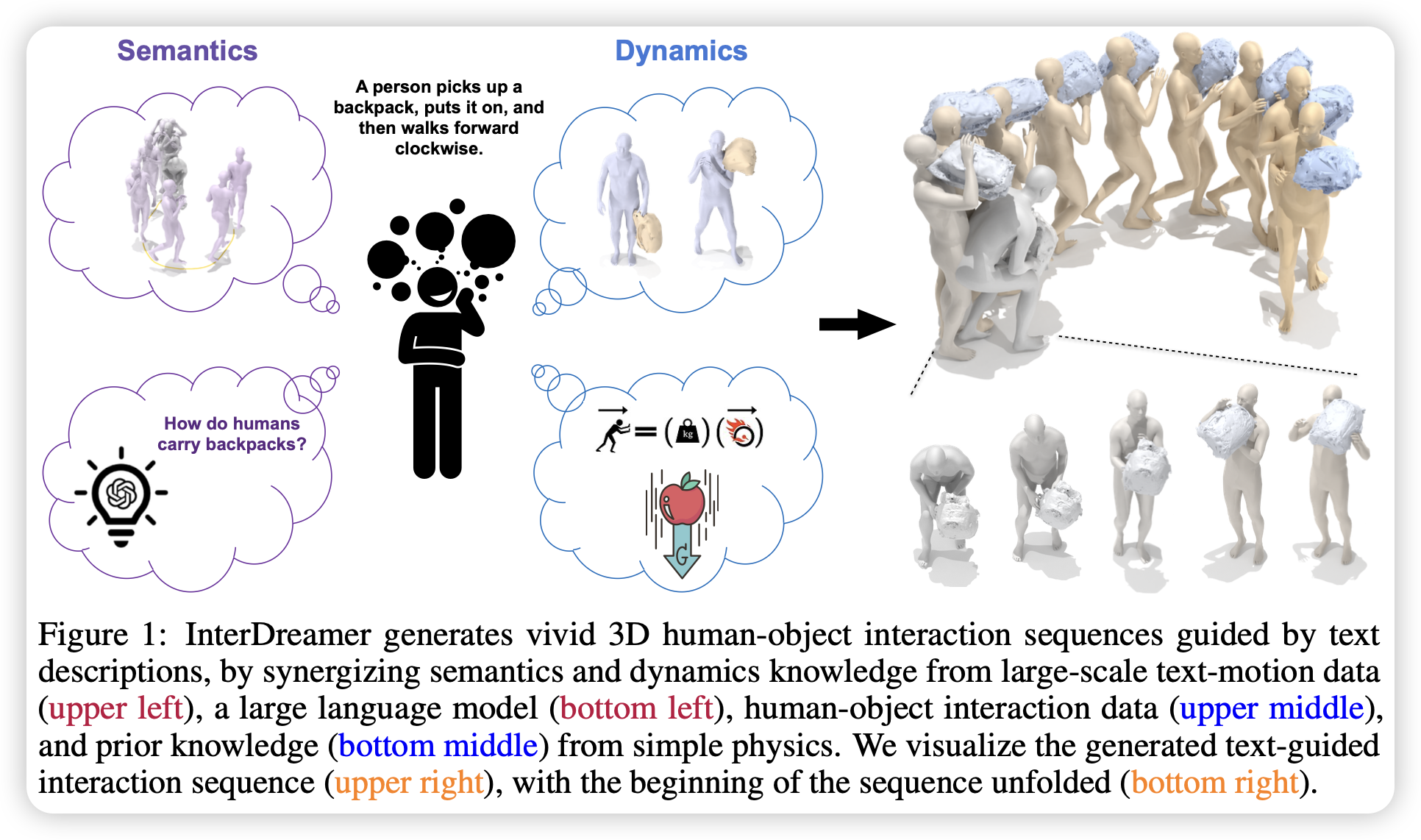
Introduction
Background
Text2Motion 技术在大规模运动捕捉数据及对应文本标注上训练的扩散模型取得了显著进展,然而推广到三维动态人体-物体交互(HOI)生成领域面临显著挑战,这类研究要么未设计物体的动态变化,要么仍依赖文本引导
- 生成社交或场景交互高度依赖大量的文本-交互配对数据
- 交互的语义无法通过直接的监督学习获得
Related Work
- 现有的人-物交互合成方法往往受限于动作范围狭窄、使用非动态物体,且缺乏完整的全身运动
- 相关研究通过标注数据集验证了监督学习方法的应用可行性,但当前可用的数据量仍显不足,促使我们探究零样本生成的潜力
- 利用大语言模型的上下文学习能力及其对检索增强生成的支持
Contribution
- 无需成对的文本-交互数据即可实现文本指令引导下合成与动态物体的全身交互任务,是一种全新的范式
- 交互语义与动态性可以解耦,提出了一个分解语义与动态的集成框架,具体由LLM,T2M Model和World Model组成,唯一要训练的是World Model
- InterDreamer能生成语义对齐且真实的HOI行为,且泛化能力超越现有的HOI数据集
Method
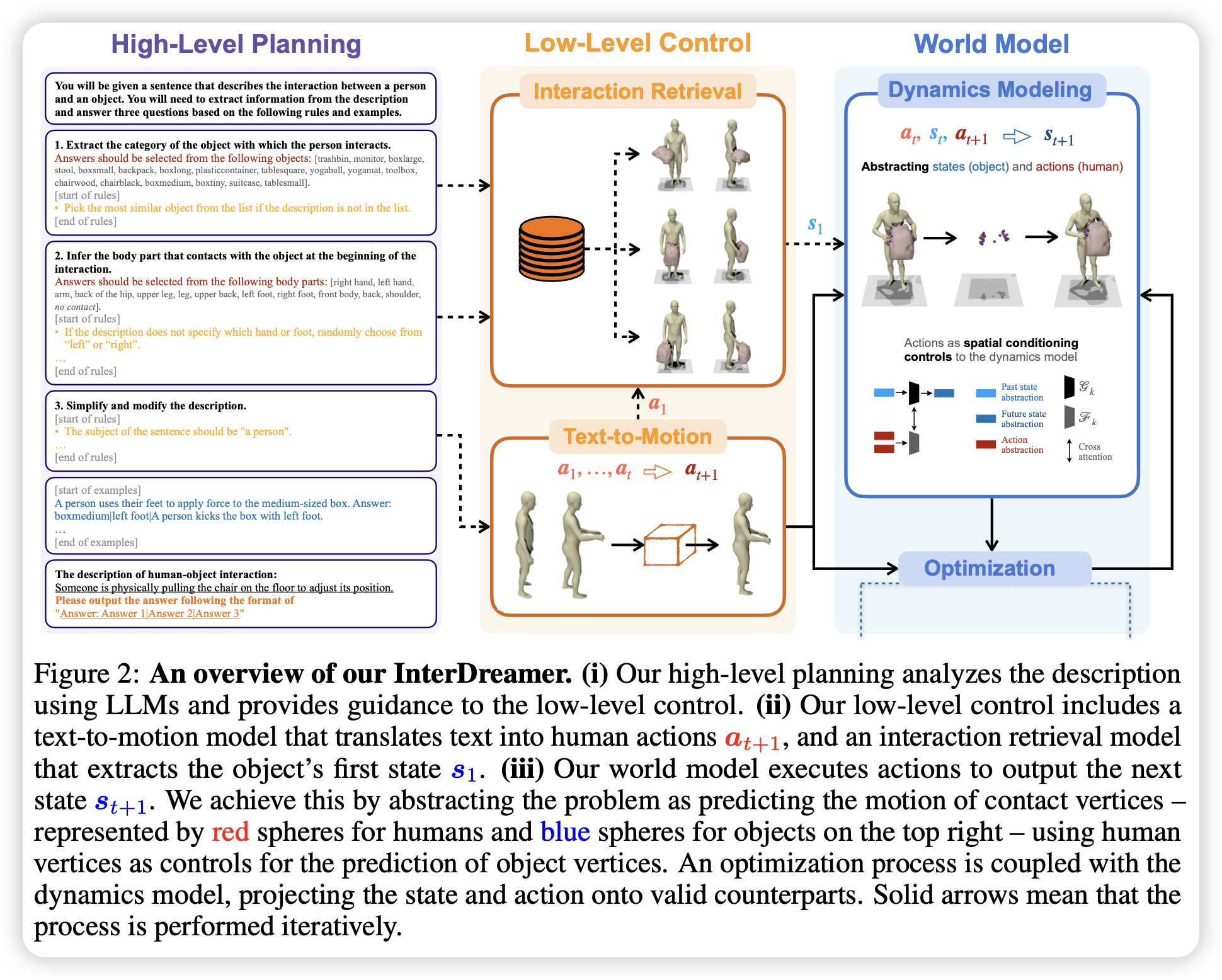
0. Definition
- 描述性文本 $p$
- 目标合成三维人-物交互序列 $x$ $x = \left[ (h_1, o_1), (h_2, o_2), …, (h_M, o_M) \right]$ $h_i$ 为基于 SMPL 模型定义的人体姿态参数 $o_i$ 为刚性物体的三维空间位置和朝向 $M$ 为序列长度,由文本 $p$ 确定 并将 $M$ 划为 $T$ 个片段,每个片段 $m$ 帧
1. High-Level Planning
通过 few-shot 和 CoT,利用 LLM(GPT-4 和 Llama-2)从描述文本中提取交互细节 $g = L(p)$
- 确定交互对象:将 $p$ 描述的对象转换为预定义列表中的对应类别: [trashbin, monitor, boxlarge, stool, boxsmall, backpack, boxlong, plasticcontainer, tablesquare, yogaball, yogamat, toolbox, chairwood, chairblack, boxmedium, boxtiny, suitcase, tablesmall]
- 确定接触部位:依据 SMPL 模型定义的部位,推断出交互涉及的部位: [right hand, left hand, arm, back of the hip, upper leg, leg, upper back, left foot, right foot, front body, back, shoulder, no contact]
- 缩小分布差距:填补了自由描述文本与 T2M 模型训练数据中所用文本之间的分布差距
2. Low-Level Control
得到交互细节 $g$ 后,先通过交互检索数据库生成与 $g$ 相匹配的物体初始状态 $s_1$,接着通过 T2M 模型(和 World Model)交替生成一系列人类动作序列 ${a_t}_t^T$
- T2M
人物下一步动作由物体当前状态、人物先前动作序列和文本交互细节决定:$a_{t+1} \sim \pi1(a{t+1} | s_t, {a_i}_i^t, g)$
人物初始动作仅由 $g$ 决定:$a_1 \sim \pi_1(a_1 | g)$,并用于交互检索
$\pi_1$ 基于现有的 T2M 模型构建:MDM、MotionDiffuse、ReMoDiffuse、MotionGPT
- 交互检索
交互检索组件 $R$ 基于人体初始动作 $a_1$ 和交互细节 $g$,建立物体初始姿态 $s_1 \sim R(s_1 | a_1, g)$
交互检索数据库由目标数据集(BEHAVE、OMOMO、CHAIRS)的训练集中逐帧扫描提取的 HOI 帧来构建,检索的 key 是(接触的人体部位,交互的物体类别),存储的 value 是一个长度为 $K$ 的顶点索引对列表:${(d_h^i, do^i)}{i=1}^K$
$d_h^i$ 是 SMPL 人体网格表面上发生接触的顶点索引($1 \sim 6890$) $d_o^i$ 是 3D 物体网格表面上对应接触的顶点索引
检索时从 key 对应的 value 中随机采样一个,接着移动和旋转物体(优化 6D 姿态)使其顶点 $d_o$ 尽可能贴近人体的 $d_h$
3. World Model
给定物体当前的状态和人体前后的动作,预测物体下一帧的状态 $s_{t+1} = \pi2(s{t+1} | s_t, at, a{t+1})$,为了能泛化到未见过的物体上,世界模型不关注物体的整体形状和人体的全身动作,只关心接触区域
- SDF 距离场筛选: 对于先前 $H$ 帧的每一帧,先计算物体表面的 SDF,如果人体的某些顶点距离物体表面小于某个阈值 $\delta_1$,并且这些点之间分散度大于 $\delta_2$,这些点会被采样为接触顶点,数量为 $N$,抽象为历史顶点轨迹 ${{vi^j}{j=1}^{N}}_{i=1}^{H}$
- 关键特征提取:
提取每个接触顶点的特征向量 $f_i^j$
- T-Pose 坐标:该顶点位于人体表面的哪个位置
- 顶点到物体表面的向量:表示了人体顶点对物体可能产生的作用力方向,还隐式包含了物体局部的形状信息
- 相对速度:人体顶点相对于距离它最近的物体顶点的速度,决定物体下一秒是被推动还是拉动
架构
- 输入(第0层)
- 物体的上一帧姿态 $x_0 = s_t$
- $N$ 个人体接触顶点的特征 ${y0^j}{j=1}^N$ 包括过去 $H$ 帧和未来 $F=m > H$ 帧的运动轨迹特征(学到更稳定、泛化的长程物理规律) 以及前面提取出的关键特征 $f^j$
- 主干网络 $\mathcal{G}$ 当人体和物体没有接触时,只有 $\mathcal{G}$ 在工作,负责学习物体在自然状态下的物理规律
- 条件控制网络 $\mathcal{F}$ 当人体接触物体时,$\mathcal{F}$ 负责提取接触顶点的特征,编码成可以影响物体运动的控制信号并通过 Cross-Attention 传入到 $\mathcal{G}$ 中:$x{k+1}, {y{k+1}^j}_{j=1}^N = \text{Attn}(\mathcal{G}_k(x_k, \Theta), {\mathcal{F}k(y_k^j, \Thetav)}{j=1}^N)$ $x{k+1}$ 为经过第 $k$ 层融合后的物体隐含状态向量, $y{k+1}^j$ 为第 $j$ 个接触顶点经过注意力交互后更新的特征向量
- 输出 物体的下一帧姿态 $s_{t+1}$
损失
通过对人体和物体的姿态参数执行梯度下降优化人体动作$a{t+1}$和物体姿态$s{t+1}$
- 预测和 GT 的拟合损失
- 保证时间平滑的速度损失
- 促进接触发生的接触损失
- 减少穿透的碰撞损失
Experiment
作者证明了 InterDreamer 在完全没有“文本-交互”成对数据的情况下,仍然能生成高质量、符合语义且物理连贯的 3D HOI 序列。
但直接与那些使用了大量配对数据进行监督学习的模型进行定量对比是不公平的,因此作者主要围绕框架中各个模块设计的必要性展开。
作者证明了模型能够很好地理解并执行训练集中不存在的复杂组合指令,并且能够直接泛化到 CHAIRS 数据集和 OMOMO 数据集,生成逼真的接触和物理反应。
Dataset
- BEHAVE中共532个用于评估的子序列
- 人体姿态采用SMPL-H建模,手部被设为平均姿态(缺少手部数据)
- 直接在World Model没见过的CHAIRS和OMOMO数据集上进行测试
Metrics
- 人体运动质量:FID、多模态和多样性、R-精度、多模态距离
- 交互质量:
- CMD:真实的与生成的 交互接触图之间 的距离
- 序列级接触图:各身体部位有效接触的时间占比定义
- 碰撞率:人体SDF中物体顶点取非负值的平均占比
- 物体运动准确性:包括平移误差和旋转误差
Baseline
- Planning:GPT-4和Llama-2
- T2M:MDM、MotionDiffuse、ReMoDiffuse、MotionGPT
- World Model:采用了四种不同的动力学控制策略
- 无条件(不考虑人体动作)
- 使用稀疏的接触标记点
- 直接输入人体原始动作
- 本文提出的接触顶点控制
Ablation
Planning & T2M
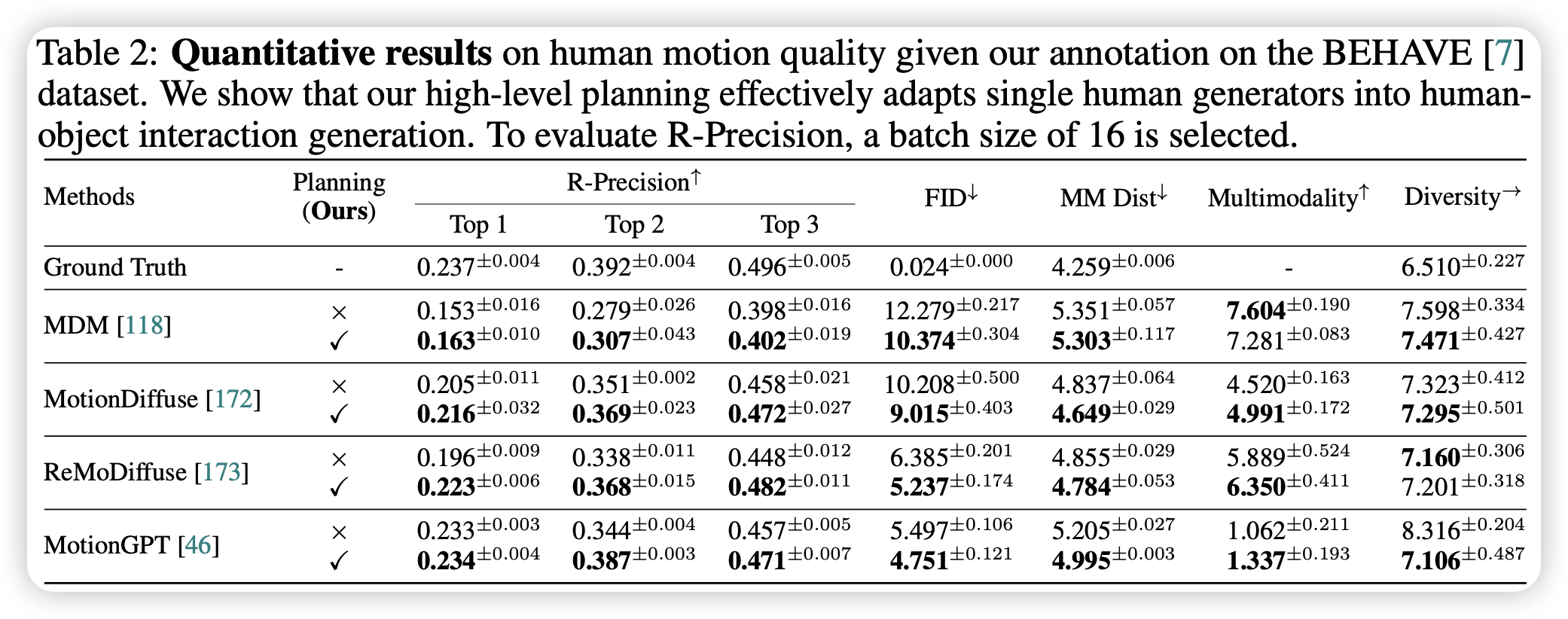
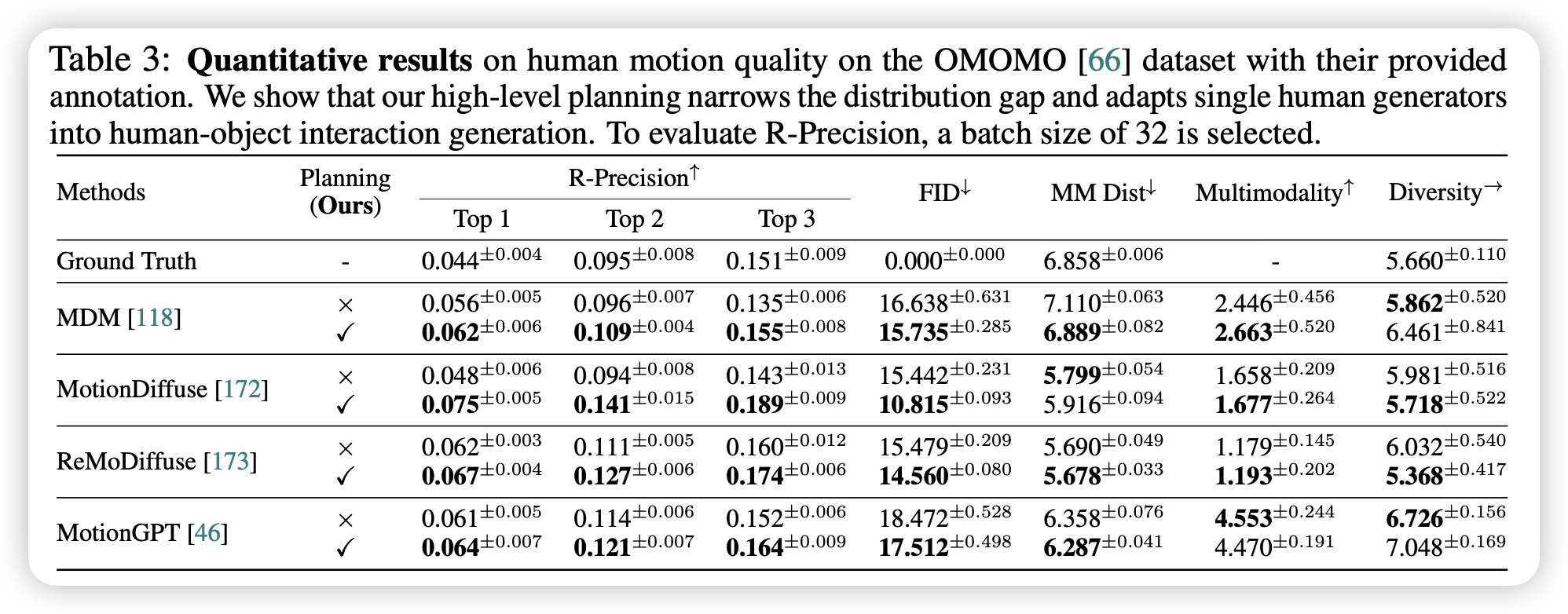
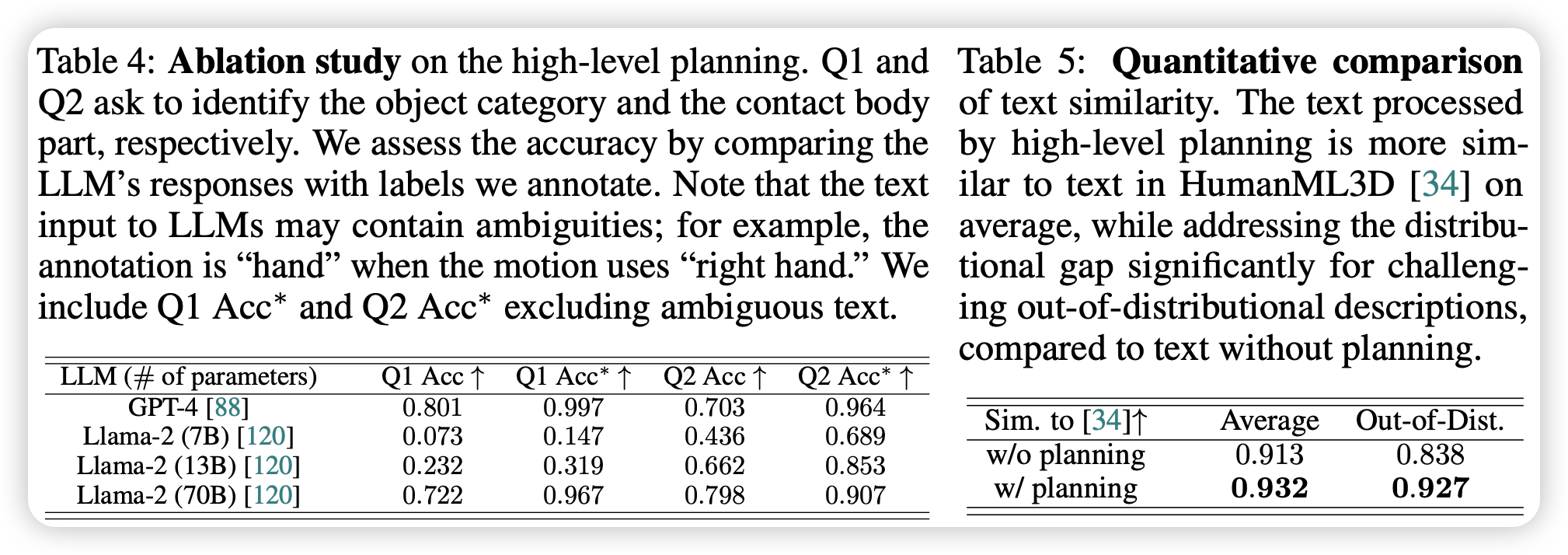
- 加入 LLM 规划后,所有 T2M 基线模型的生成质量都得到了大幅提升
- LLM 的参数量很重要,该框架需要具备强大推理能力的 LLM
- 通过提取文本的 CLIP 特征并在 t-SNE 上可视化可以发现,经过高层规划改写后的描述词,其在隐空间中的分布特征被强行拉平,变得与 T2M 模型训练时使用的数据集(HumanML3D)的文本特征高度相似
World Model
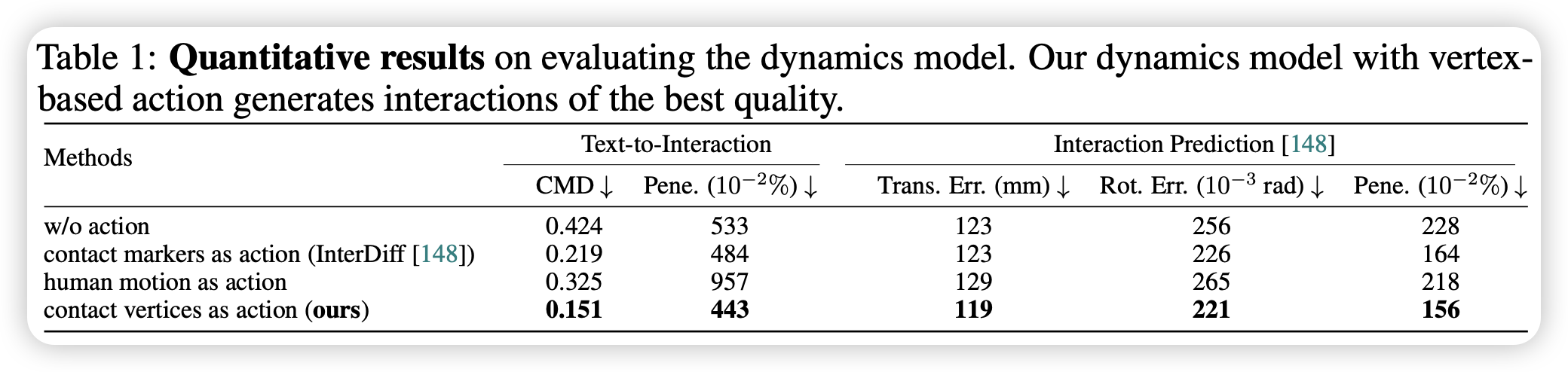
- 相比于没有任何动作引导,它显著降低了穿透率和接触图误差(CMD)
- 相比于直接输入全身动作,顶点控制过滤掉了无关身体部位的噪音,提供了更细粒度的物理引导,从而获得了更好的动力学预测精度