- https://craigleili.github.io/projects/hoipage/
- https://github.com/craigleili/HOI-PAGE
- ICML 2026; Cited by 0
- Lei Li, Angela Dai; Technical University of Munich
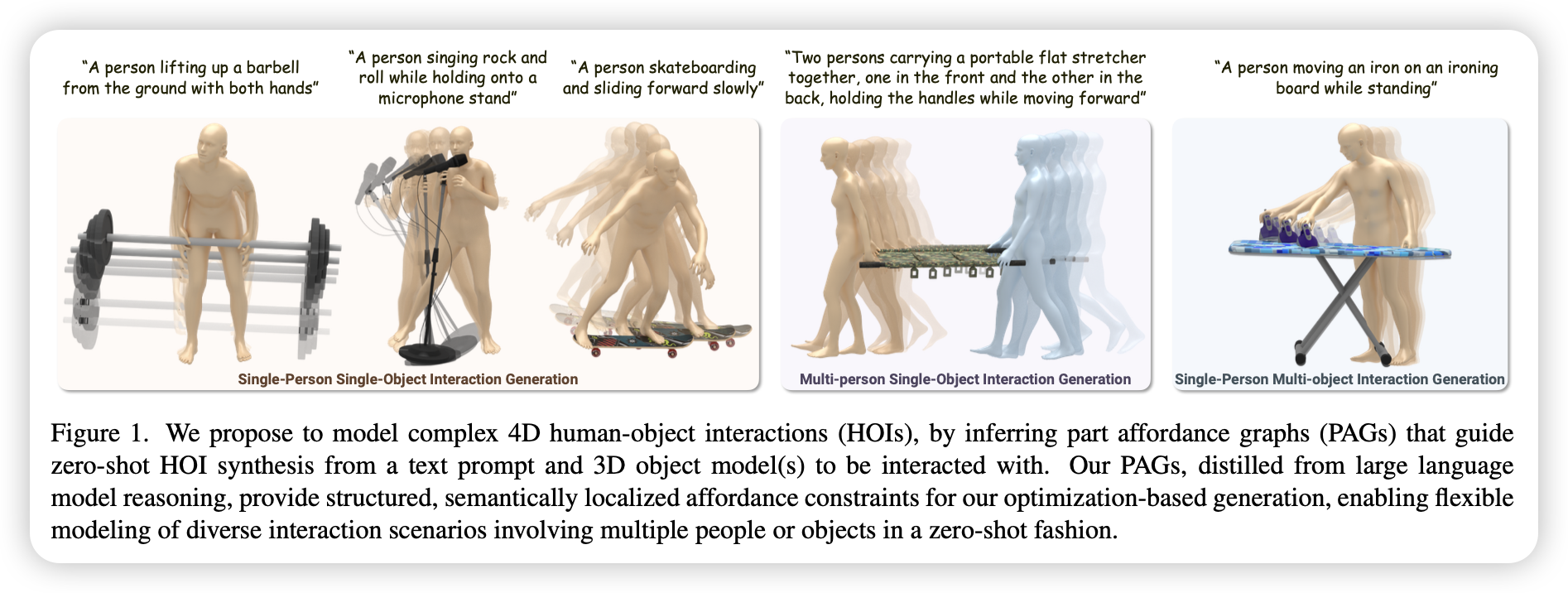
Introduction
Background
- 以往的4D生成方法通常将人体和物体作为整体来建模,缺乏对“特定人体部位如何接触特定物体部位”的细粒度理解,导致生成的动作往往缺乏真实感
- 现有的先进生成模型高度依赖真实数据进行监督训练,然而收集此类数据及其昂贵且耗时,并且很难处理多人或多物体交互的场景
Related Work
- GenZI提出通过从文本到图像基础模型中提取先验知识,生成静态交互效果而无需三维交互训练数据
- 已有研究规避对四维真实标注训练数据的需求,着手解决零样本四维HOI合成的难题,但仅对人-物运动进行全局处理
- PiGraphs提出捕捉人体部位与3D场景之间的物理接触和视觉注意力关系,从而生成交互的静态快照
- Fisher等人提出人物-场景交互中学习活动热图表示
- iMapper提出利用场景片段作为先验,从单目交互视频观测中重建HOI
Contribution
- 第一次提出用LLM提取结构化的部件可供性图(PAGs),捕捉人类如何与特定物体部件进行交互,以指导接下来的合成过程——3D物体部件分割、HOI参考视频生成、4D HOI优化
- 提出了一种基于PAGs的优化方法,能实现更精确的部件级接触
- PAGs灵活且通用,且能泛化到多种交互场景,包括多人/多物
Method
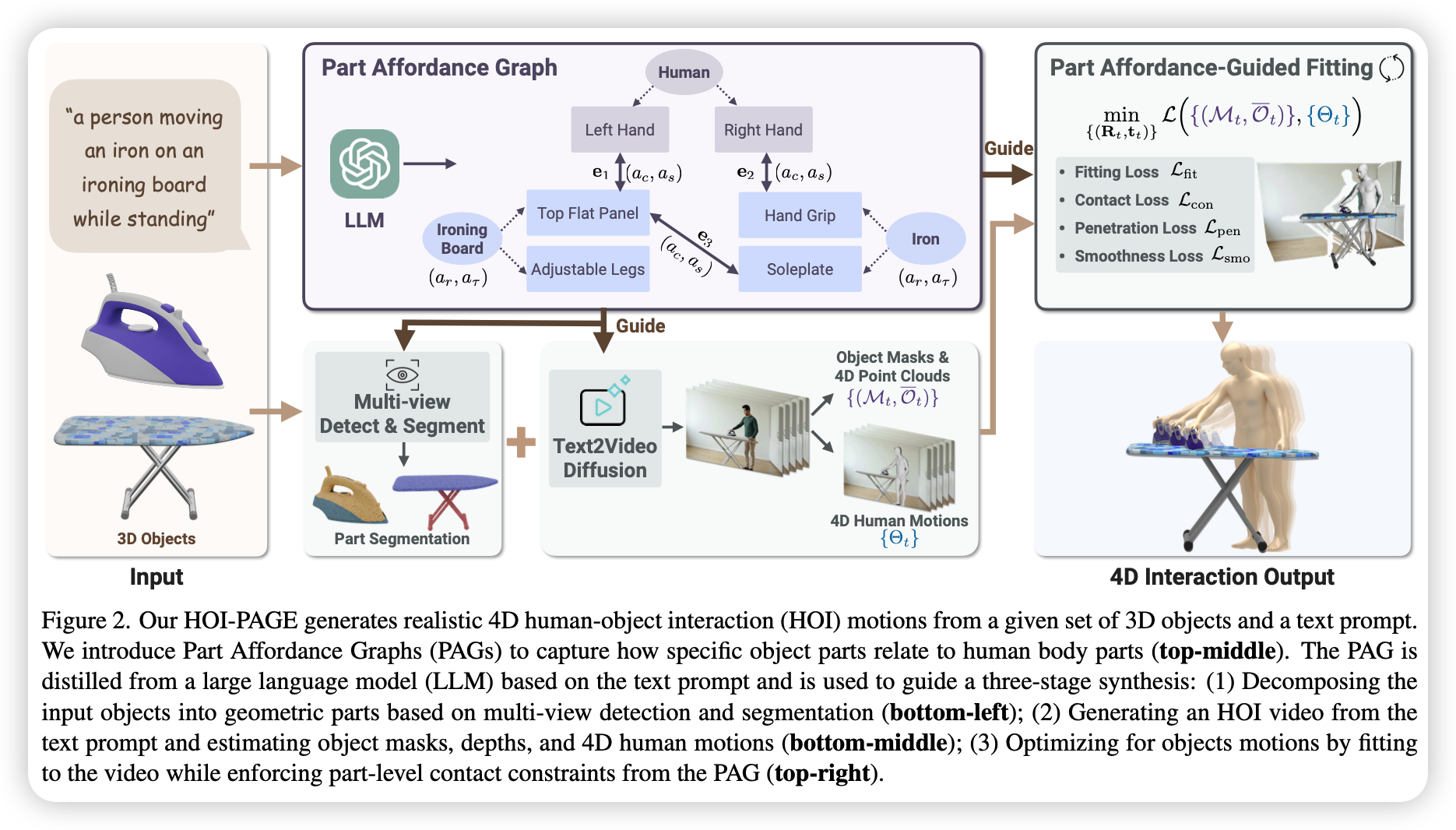
0. Definition
- 输入:
- 待交互的 3D 物体点云
- 期望人类交互的简短文本提示
- 输出
- ${ \mathcal{\theta}_{t=1}^T }$:$T$ 帧人类 SMPL-X 参数
- ${ (R_t, tt) }{t=1}^{T}$:$T$ 帧 3D 物体的旋转和平移姿态
1. PAG
将 PAG 定义为 $G = (V, E)$
$v\in V = V_h \cup V_o$ 表示人体和物体部件集合。此外向 $V$ 中添加虚拟父节点 $\bar{v}$ 表示整个人类或物体,与其所有部件节点相连,并拥有两个运动属性 $(ar, a{\tau})$,表示在交互过程中是否发生全局旋转和全局位移,如果都为 $false$,那整个交互过程中应保持静止。
$e \in E$ 表示物体节点与人体或物体节点之间的接触关系,拥有两个属性 $(a_c, a_s)$,表示接触在 $T$ 帧内是否连续,以及是否相对静止。
利用 LLM 根据输入提示词构建 PAG:
- 输入:包含待交互的 3D 物体列表和一句简短的交互文本描述的 JSON 数据
- 输出:一个包含人类数量、物体节点、人体节点、交互边及其属性、物体/人体全局状态,以及一段扩写后的包含完整交互信息的 150 字详细描述的 JSON 数据
- 规则:
- 只能从预设的 12 个基础人体部位中选择人体部位节点,包括左/右手、左/右臂、左/右肩、左/右腿、左/右脚、头部、臀部
- 必须明确具体的人体/物体部件,不能用“手”、“表面”、“边缘”等模糊词汇
作者尝试通过用文本提示词与 3D 物体渲染图来提示视觉语言模型(如 VLMs)构建 PAG,但模型由于幻觉问题偶尔会忽略视觉输入导致精度较差,并且鲁棒性也较低。
PAG 可灵活的扩展节点集和边集来表示不同类型的交互,如多人/多物交互。
2. 多视角物体部件分割
- 输出:各物体部件的 3D 点云
系统先将 3D 物体放置在一个虚拟环境,并在周围的“视点球”上均匀采样 8 个虚拟相机的拍摄角度,渲染为 8 张不同角度的 2D 图像。
将一物体的各部件名称,结合其 8 张图像,输入视觉大语言模型 Qwen-VL,在每张图片中框出目标部件的 2D 边界框。
进一步将 2D 边界框输入给 Meta 的 SAM2 模型,将该部件在图像中的像素级掩码提取出来。
最后针对 3D 物体表面的每一个点,统计它在多少个相机视角下被判定为某个部件,通过“投票机制”最终确定输入哪个部件,最终一个整体的 3D 物体 $\mathcal{O}$ 被精确地分割为了多个 3D 点云集合 ${ \mathcal{P}^o}$。
整个流程不需要任何 3D 层面的人工标注数据,实现了零样本 3D 语义分割。
3. 生成 HOI 视频
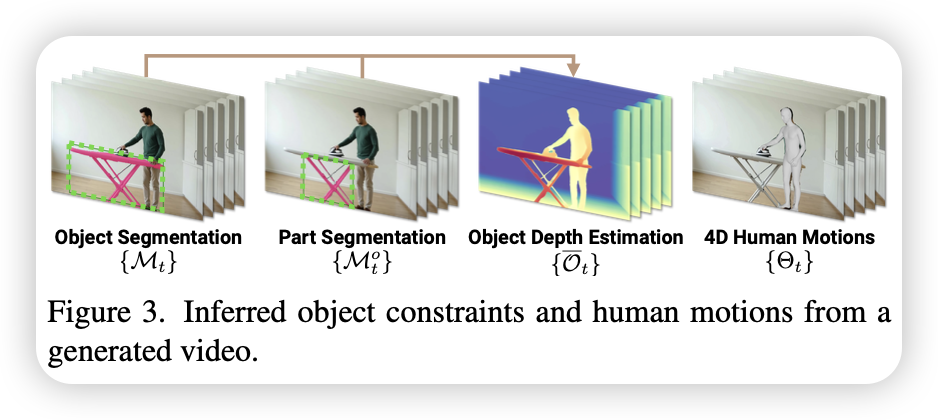
- 输入:先前 LLM 扩写的文本提示词 $\Gamma^+$
- 输出:视频每一帧的人体精确 3D 姿态、物体及其各部件的 3D 点云
首先用 $\Gamma^+$ 通过高质量的文生图模型 FLUX 生成视频的第一帧(会先生成 5 张候选图像,然后调用 VLM 挑选出最完美的一张),以确保视频生成的稳定性和质量,然后调用视频扩散模型 CogVideos 生成一段连续的 49 帧 2D 交互视频。
接着在视频的第一帧上使用 Qwen-VL 框出每个物体的边界框,然后交给 SAM2 让它在后续的视频帧里追踪并扣出每个物体及其部件的 2D 掩码${M_t^O}$和${M_t^o }$。
然后使用单目深度估计模型 MoGe 来推测视频每一帧中每个像素的深度信息,将深度信息和上一步得到的 2D 掩码结合起来,就能计算出视频中物体及其部件在每一帧的 3D 点云数据。
对于视频中的人物,使用人体运动恢复模型 GVHMR,直接从视频中估算出人物在每一帧的 3D 骨骼和体型参数(SMPL-X)。
4. PAG引导的4D HOI优化
通过先前三个步骤得到的PAG、带有语义分割的3D物体模型、4D人体参数和物体3D点云轨迹,优化3D物体在每一帧的旋转$R_t$和平移$t_t$参数,让物体在3D空间中的运动既完美契合2D视频画面,又能严格遵守物理规则和语义约束。
$\mathcal{L}{total} = \lambda{fit}\mathcal{L}{fit} + \lambda{con}\mathcal{L}{con} + \lambda{pen}\mathcal{L}{pen} + \lambda{smo}\mathcal{L}_{smo}$
-
拟合损失(CD为倒角距离)
- $\mathcal{L}{\mathrm{3D}}^O=\sum{O} \sum_{t=1}^{T} \mathrm{CD}(R_tO + t_t, \bar{O_t})$
- $\mathcal{L}{\mathrm{3D}}^o=\sum{O}\sum{p^o} \sum{t=1}^{T} \mathrm{CD}(R_t p^o + t_t, \bar{p_t^o})$
- $\mathcal{L}{\mathrm{2D}}^O$和$\mathcal{L}{\mathrm{2D}}^o$为将3D物体投影到2D屏幕上, 计算与视频像素级掩码的CD损失。
物体级别的拟合能弥补物体语义分割可能存在的不准确; 部件级别的拟合能提供高级别的语义引导,防止陷入局部最优解。
-
接触损失(MD为两点云之间的最小距离)
- $\mathcal{L}{cc}=\sum{e=(v_1, v2) \in E} \left{ \begin{aligned} \frac{1}{T}\sum{t=1}^T \mathrm{MD}(P_t^{v1}, P_t^{v2}) & \quad if \; a_c = true \ min_t MD(P_t^{v1}, P_t^{v2}) & \quad otherwise \end{aligned} \right .$
如果持续接触,计算两个点云之间的平均最小距离,否则只计算最小距离
- $\mathcal{L}{cd}=\sum{e=(v_1, v_2)\in E} \sum_t \left{ \begin{aligned} & \mathcal{L}_2 (P_t^{v_2 \rightarrow v1}, P{t+1}^{v_2 \rightarrow v_1})\quad & if \; a_s = true \ & \mathcal{L}_2 (P_t^{v_2 \rightarrow v1}, \frac{1}{2}(P{t-1}^{v_2 \rightarrow v1}, P{t+1}^{v_2 \rightarrow v_1})) \quad & otherwise \end{aligned} \right .$
如果相对静止,在同一坐标系下计算每一帧两个点云之间的相对距离, 否则只要求相对运动轨迹具有时间上的连贯性。
-
穿透损失 预先计算每个物体的SDF,然后计算所有人体-物体对的穿透损失。
-
平滑损失
- $\mathcal{L}_r = \sum_O \sum_t \left{ \begin{aligned} & \mathrm{GD}(Rt, \frac{1}{2}(R{t-1}, R_{t+1})) \quad & if \; a_r=true \ & \mathrm{GD}(Rt, R{t+1}) \quad & otherwise \end{aligned} \right .$
- $\mathcal{L}_\tau = \sum_O \sum_t \left{ \begin{aligned} & \mathrm{GD}(tt, \frac{1}{2}(t{t-1}, t{t+1})) \quad & if \; a\tau=true \ & \mathrm{GD}(tt, t{t+1}) \quad & otherwise \end{aligned} \right .$
如果物体有全局旋转或位移,会尽量让相邻帧之间的轨迹平滑,否则限制其在时间轴上的变化。
使用A100通过梯度下降对$\mathcal{L}_{total}$($R_t$和$t_t$)优化600步,单物体优化耗时约6分钟,双物体约10分钟。并且为了防止由于倒角距离导致收敛到局部最优,会尝试4种不同的初始旋转角度来寻找最优结果。
Experiment
Dataset
从Sketchfab网站收集了24个日常用品的带纹理3D网格模型,为每个物品预先计算SDF,并准备了16条单人单物交互的文本提示,以及5个多人/多物的。
Metric
- 人类感知:A/B对比和1-5打分
- 语义对齐:用VideoCLIP计算文本与HOI渲染视频的余弦相似度
- 运动多样性:为每个文本提示生成5个HOI样本,计算每对样本之间的距离
- 物理合理性 & 人体/物体运动平滑性
Baseline
- HOI-Diff
- CHOIS
Result
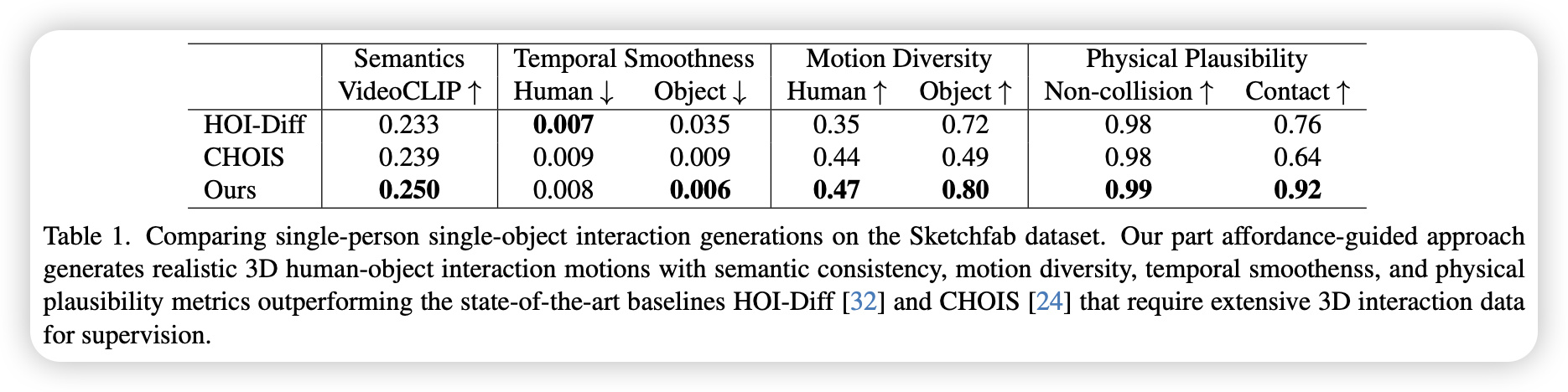
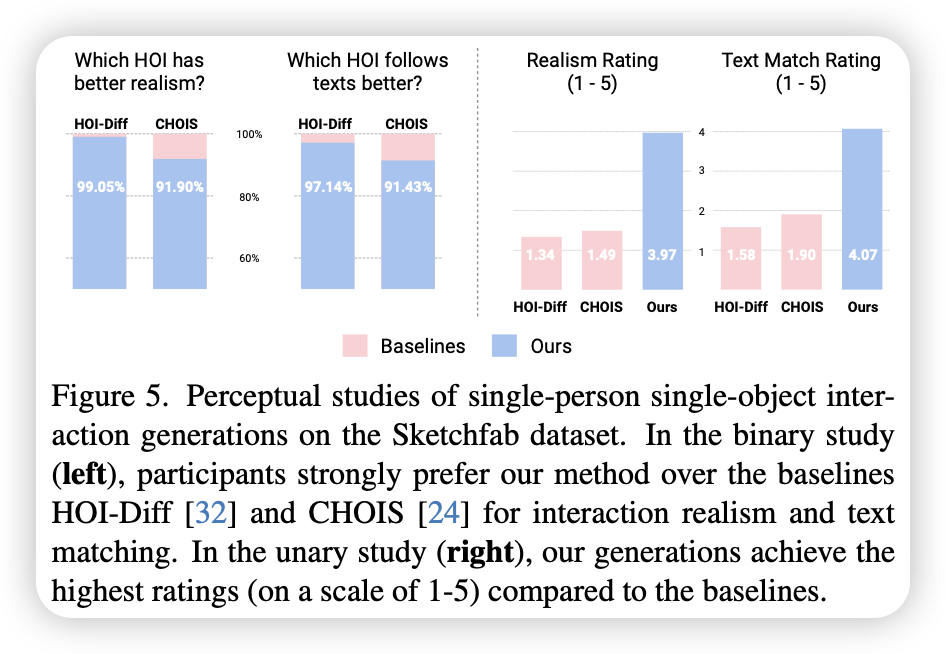
- 人类感知占据绝对优势
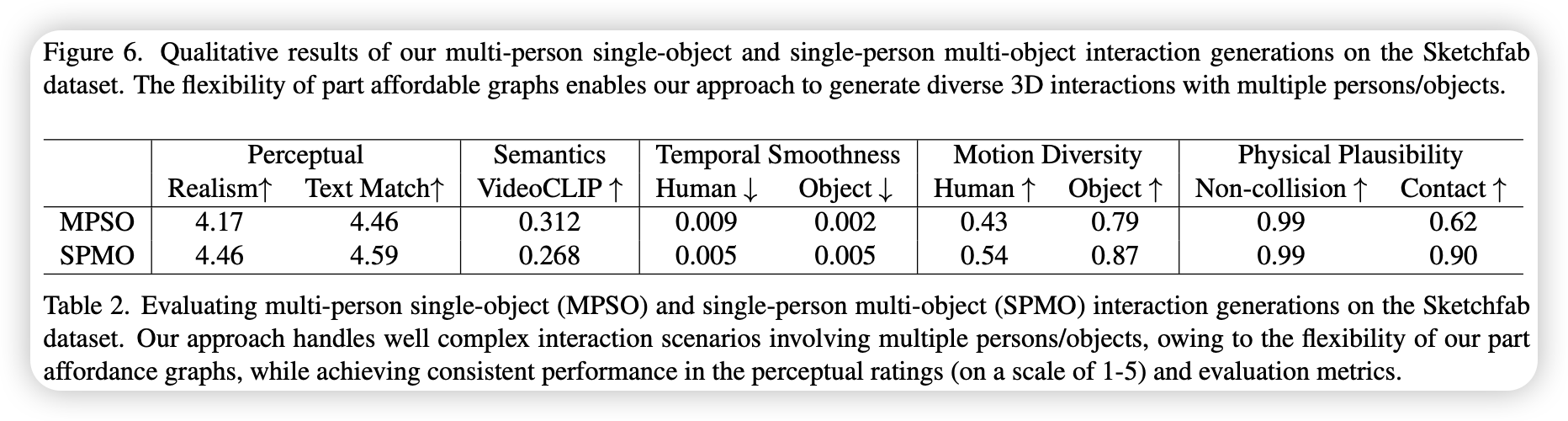
- 在语义对齐、物体运动平滑、运动多样性、物理合理性上均取得最佳成绩
- 在零样本场景下能更好的泛化到不同的物体
- 零样本PAG能合成更通用、更复杂的交互场景
Ablation
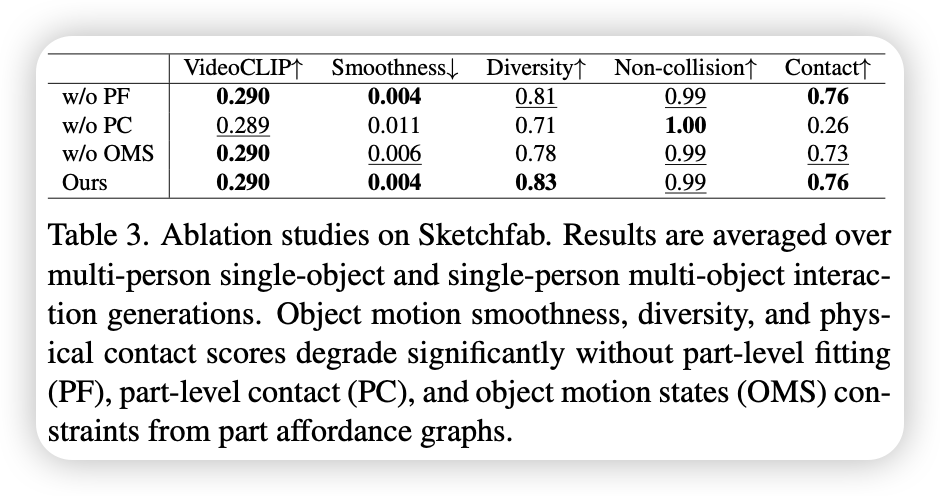
- w/o $\mathcal{L}_{fit}$(拟合约束)会失去高级语义一致性
- w/o $\mathcal{L}_{con}$(接触约束)会遗漏重要的接触关系
- w/o $\mathcal{L}_{smo}$(平滑约束)会导致错误的物体全局状态
Limitation
- PAG难以对部件的精细运动建模
- 合成结果受生成的首帧图像或视频影响