
- https://neu-vi.github.io/HOI-Diff/
- https://openaccess.thecvf.com/content/CVPR2025W/HuMoGen/html/Peng_HOI-Diff_Text-Driven_Synthesis_of_3D_Human-Object_Interactions_using_Diffusion_Models_CVPRW_2025_paper.html
- https://github.com/neu-vi/HOI-Diff
- CVPR 2025; Cited by 112
- Xiaogang Peng, Yiming Xie; Northeastern University
Introduction
Background
- 物体形状的多样性使得人与物体之间生成语义上有意义的接触以避免物体漂浮的难度尤其大
- 人类与同一物体存在多种合理的交互方式,具备多样化交互方式且忠实于输入的文本提示的 文本驱动的 HOI 合成尚未得到充分解决
- 现有的 3D 人类运动数据集要么缺乏多样的交互,要么缺乏包含交互身体部位和动作细节的高质量文本描述
Related Work
- 仅能为静态物体的 HOI 合成逼真的人体运动,通常生成给定人物姿态与最终交互姿态之间的运动,忽略了交互过程中物体的移动
- 现有针对动态物体的运动生成方法未能充分反映现实世界的复杂性,如:聚焦于抓取小物体、仅考虑少量交互类型、仅研究单一类型的物体
- 将场景几何信息作为条件有助于理解人与场景的交互关系,但缺乏成对的完整场景-运动数据
- OMOMO 可根据物体运动生成人物全身运动,但需要将物体运动作为输入
- 某些方法依赖初始状态和物体路径点,这会降低运动多样性
- 逐点预测接触标签极具挑战
Contribution
- 可实现人类以多样方式与不同类型物体进行交互,交互效果既符合物理规律,又能在语义上与文本提示保持一致
- 将 3D 人-物交互合成解耦成三个模块:粗粒度交互生成、可及性预测扩散模型、可及性引导的交互修正
- 为 BEHAVE 数据集的每个视频序列都标注了文本描述,缓解了文本驱动的 3D 手部-物体交互生成任务中严重的数据稀缺问题,并在双手操作的 OMOMO 数据集上证明了我们方法的泛化性
Method
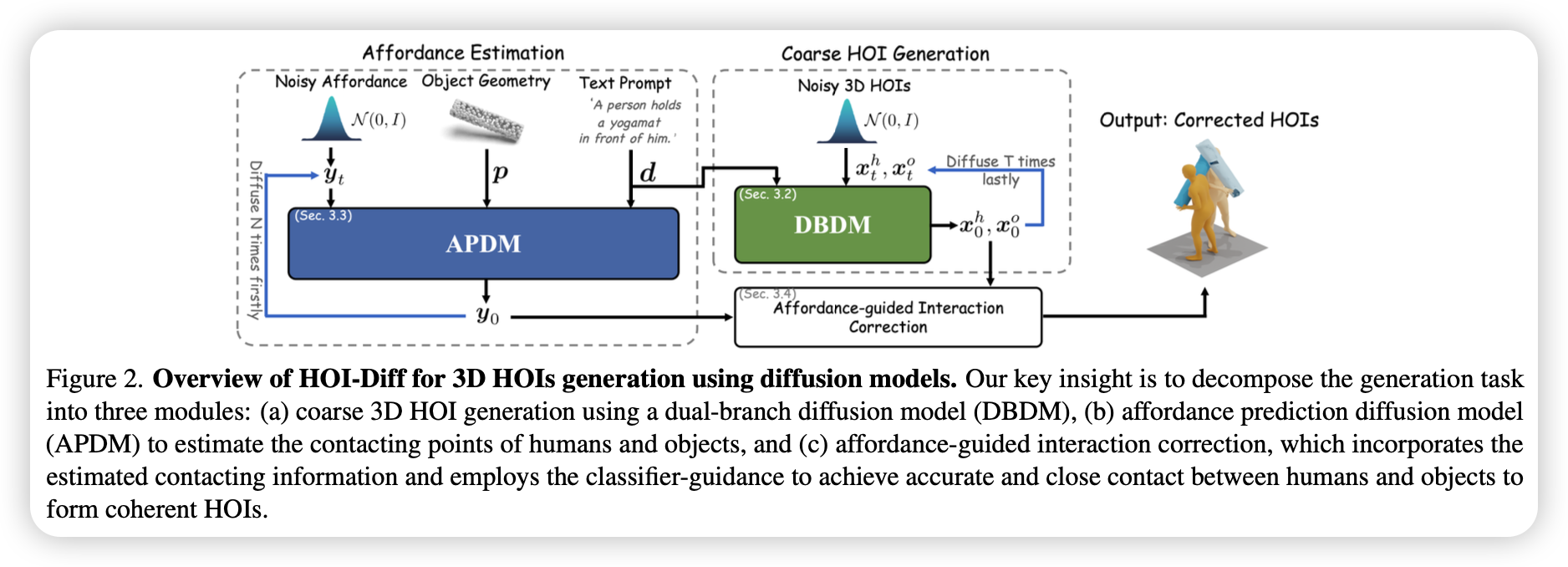
0. Definition
- 3D HOI 序列 $x = {x^h, x^o}$ $x^h \in R^{L \times D^h}$,$x^o \in R^{L \times D^o}$ $L$ 为序列长度,$D^h=263$ 为通用人体姿态参数 每个物体由 $p \in R^{512 \times 3}$ 点云表示 $D^o = 6$ 表示只优化物体的 6DOF 姿态
- 输入:文本描述 $d$ 和物体点云 $p$
- 输出:3D HOI 序列 $x$
1. DBDM
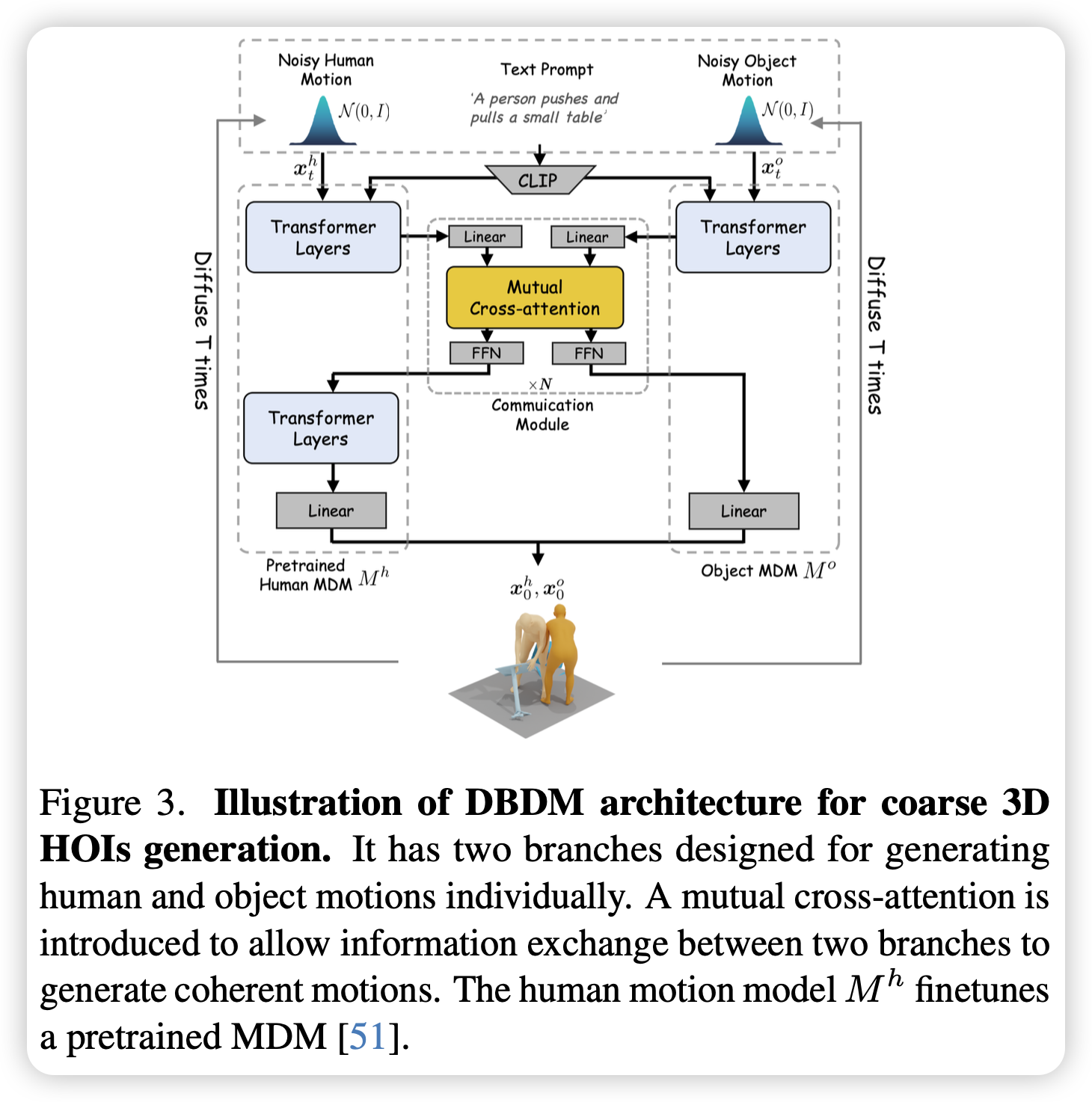
提出一种双分支扩散模型来分别生成大致连贯的人体与物体运动,包含两个 Transformer 即人体 MDM($M^h$)和物体 MDM($M^o$)。
- 输入:时间步 $t$,带噪人类运动 $x_t^h$ 和物体运动 $x_t^o$
- 输出:清晰的人类运动 $x_0^h$ 和物体运动 $x_0^o$
在生成时引入一个通信模块(CM)增强人-物交互的学习,CM 接收来自 $M^h$ 和 $M^o$ 的中间特征,基于 Cross-Attention 生成优化的更新结果,输出被插入到 $M^h$ 的第 4 个 transformer 层以及 $M^o$ 的最后一层。
由于 3D 人-物交互生成的数据可用性有限,训练中采用预训练的 $M^h$ 并对其微调,对于确保生成的人体运动的平滑性至关重要。而 $M^o$ 修改了输入和输出的线性层并从零开始训练。
如果直接把人和物体放在一个模型里训练,由于输入输出的改变必须从零开始训练,而 BEHAVE 数据集过小,会导致运动质量大幅下降。
2. APDM
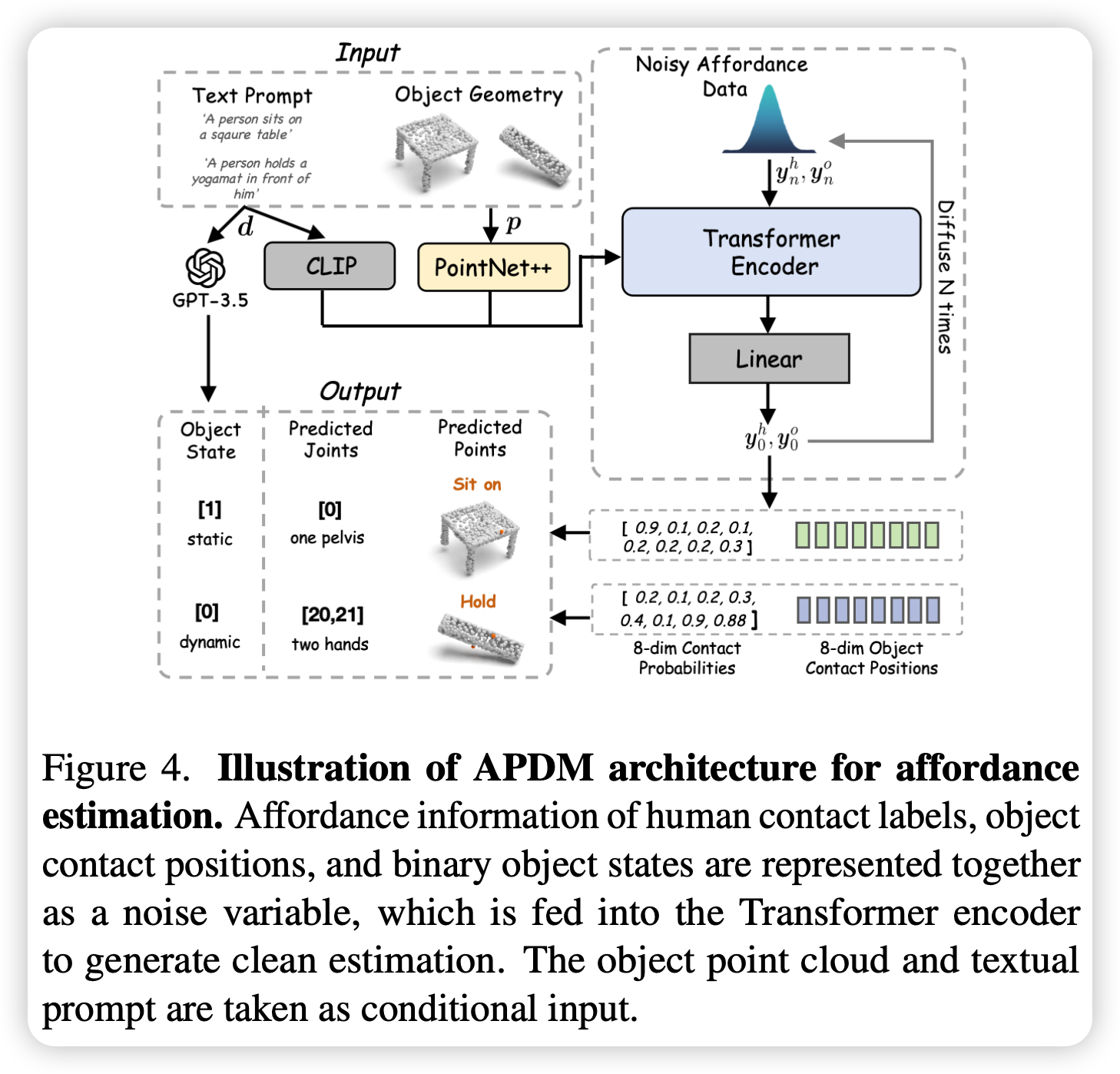
由于人-物交互的复杂性,仅靠 DBDM 通常无法生成物理合理的结果,可能导致物体漂浮或穿透。为了提升效果,需要先确定人-物之间接触区域的位置。
InterDiff 是等人-物的动作都生成完之后再由距离计算接触点,但如果前面生成的动作本身就是错的,接触点也会算错,并且无法对生成的动作进行修正。
而 APDM 的预测完全不依赖 DBDM,它能提供正确的接触点信息从而后续纠正,并且即使是同一物体和统一交互类型,接触区域也存在多样性,其能随机生成接触点保证生成运动的多样性。
由于直接预测 3D 点云上所有点的接触情况及其困难,APDM 只关注人体在交互中常用的八个关节:[骨盆、脖子、双肩、双手、双脚]。预测的结果包括八个关节的接触概率 $y_0^h \in {0, 1}^8$(超过 0.6 判定为发生接触)和发生接触的关节对应在物体表面上接触的坐标 $y_0^o \in R^{8\times3}$。
此外确定交互过程中物体“动”(如拿起)还是“静”(如坐在上面)非常关键,APDM 引入 GPT-3.5 判断,输出 0(静)或 1(动)的标签 $y_0^s \in {0, 1}$,用来约束后续静止物体的动作生成。
- 输入:文本提示 $d$ 和物体点云 $p$
- 特征提取:CLIP 提取 文本特征,PointNet ++ 提取点云特征
- 输出:$y = (y_0^h, y_0^o, y_0^s)$
3. Interaction Correction
结合 APDM 的结果,使用分类器引导来实现人体和物体之间精准且紧密的接触,以显著减少物体悬浮的情况。
定义了一个解析函数 $G(\mu_t^h, \mu_t^o, y_0)$,用于评估生成的人体关节与物体的 6DOF 位姿与预期目标的贴合程度,要求接触位置彼此接近并且二者运动在时间上保持平滑。
在每个去噪步骤 t,会计算 G 的梯度,然后对人体和物体的姿态进行扰动:
- $\mu_t^h = \mu_t^h - \tau_1 \sumt \nabla{\mu_t^h}G$
- $\mu_t^o = \mu_t^o - \tau_2 \sumt \nabla{\mu_t^o}G$
由于物体运动特征比较稀疏,其引导强度$\tau_2$比人的$\tau_1$更大;也并且由于人体动作复杂,所以希望物体主动去贴合人。
此外为了消除扩散模型在去噪阶段可能抑制引导信号,所以在去噪的最后一步,反复迭代扰动了 $K$ 次。
$G = G{con} + \alpha G{sta} + \beta G_{smo}$
- $G{con} = \sum{i \in {1,2,...,8}} ||R(\mu_t^h(i)) - V(\mu_t^o, y_t^o(i))||^2$
- $R$ 用于将当前时间步 $t$ 预测出的人体第 $i$ 个关节的局部坐标转换为全局绝对坐标
- $V$ 用于将 DBDM 预测出的物体 6DOF 姿态和 APDM 预测出的第 $i$ 个接触点 计算接触点在全局空间中的坐标
- 即把人体的八个关节和物体的接触点的全局坐标算欧氏距离
- $G_{sta} = y0^s \cdot \sum{l=1}^L ||\mu_t^o(l) - \bar{\mu}_t^o||^2$
- 方差计算,当物体应该保持静止时,计算每一帧的物体姿态与整段平均姿态的差异
- $G{smo} = \sum{l=1}^{L-1} ||x_0^o(l+1) - x_0^o(l)||^2$
- 计算物体在相邻两帧之间的位移变化量,要求物体从一帧到下一帧不要发生瞬移,确保运动轨迹在时间维度上是平滑的
Experiment
Dataset
BEHAVE
BEHAVE 包含了8个人与20种不同物体的真实交互动作,作者为这些视频序列人工标注了交互类型和接触部位,并利用 CPT-3.5 进行润色和扩写,最终得到 1451 个 3D HOI 序列。
OMOMO
OMOMO 聚集于手部的全身操作任务,包含日常生活中 15 种物体的人机交互动作。
Metric
- 人类运动质量:FID、R-Precision、Diversity
- 物理合理性:接触距离、足部打滑率、穿模程度
Baseline
现有的 T2M 方法均为涉及 3D HOI 生成,因此主要聚焦于评估人体运动生成性能,并设计 baseline 的变体来对比 HOI 效果
- MDM$\dag$:用 BEHAVE 对原始 MDM 微调
- MDM*:修改输入输出层的维度,同时把人和物体作为一个整体来学习
- PriorMDM*:最初用来生成“双人交互”的模型,把它的一条分支改造成了生成物体
- InterDiff*:加上 CLIP 来支持文本驱动任务
Result
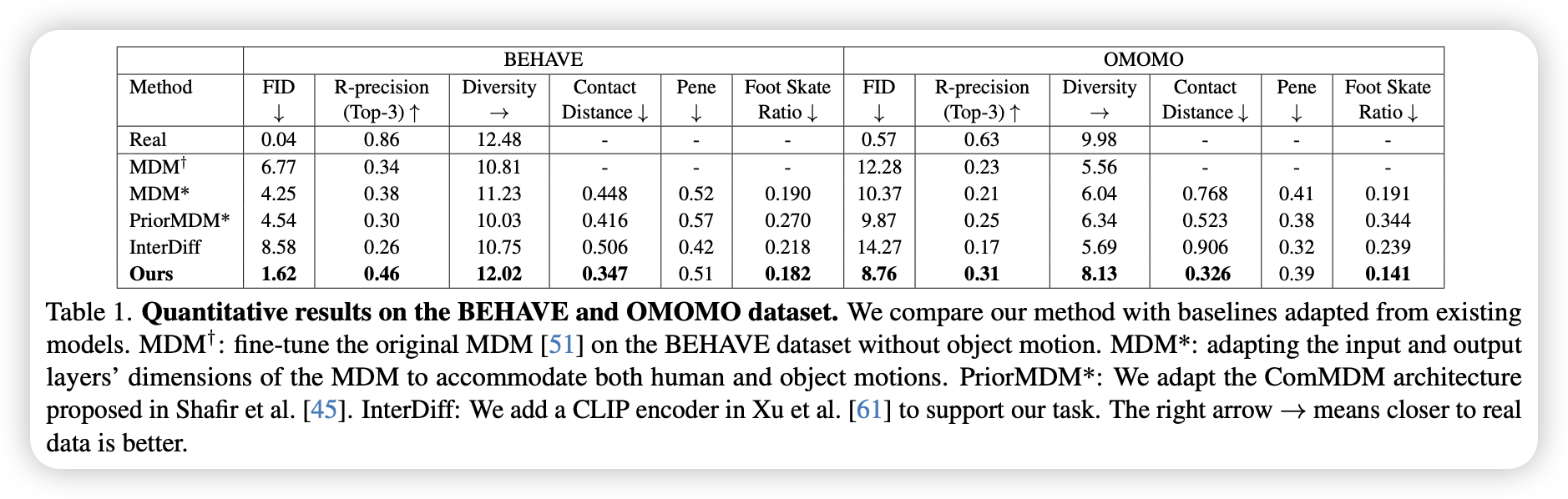
- Ours 在 FID、R-Precision和Diversity都达到了SOTA
- Ours 接触距离最小
- 用户绝大部分更偏爱 Ours
- Ours 可以泛化到未见的物体
Ablation
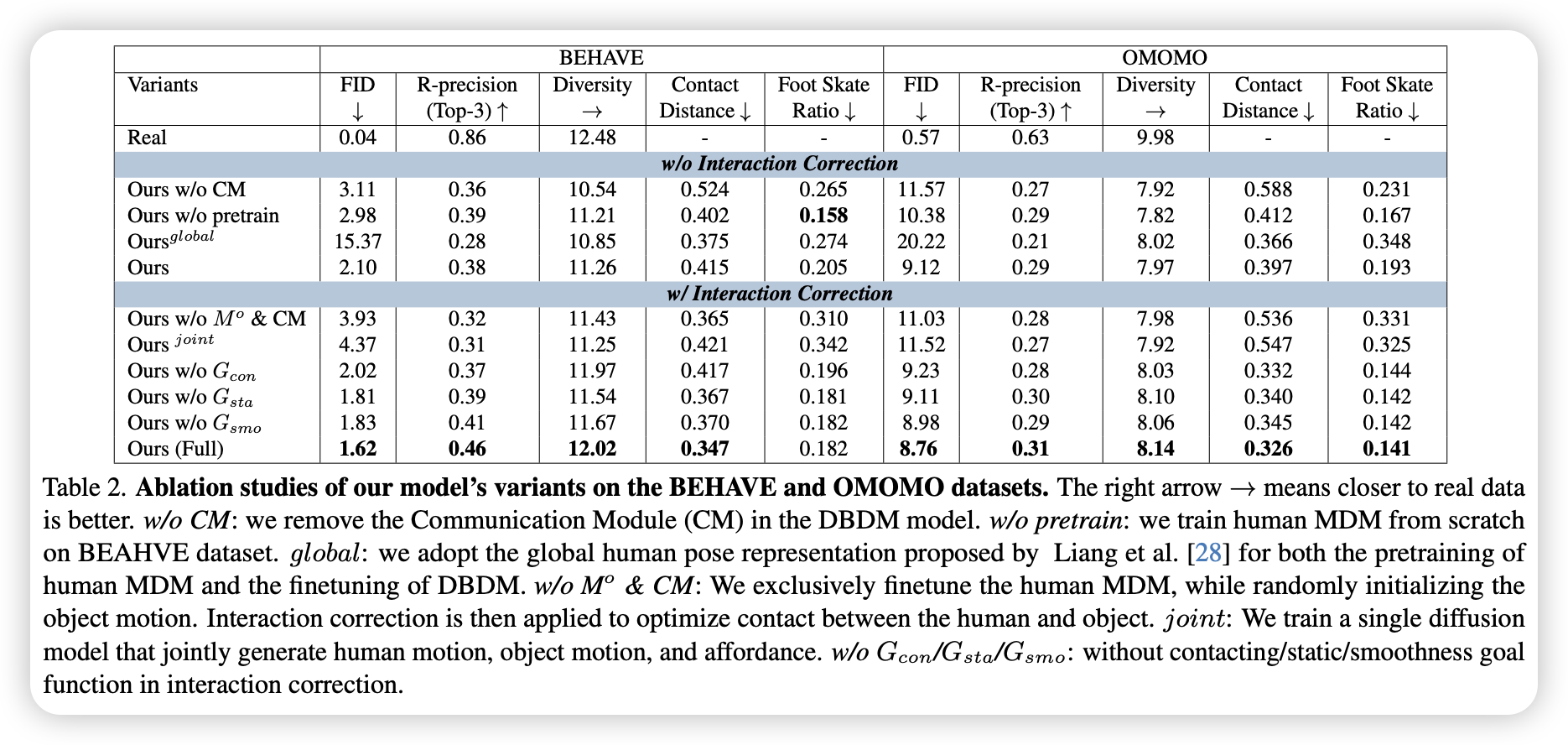
- 抛弃物体 MDM,只使用 IC 效果很差; 并且 IC 能生成更好的 HOI
- 去掉 CM 后,所有指标大幅下降,尤其是接触距离
- 人体和物体 MDM 需要单独建模, 并且利用预训练的人体 MDM 效果更好
- 联合训练 DBDM 和 APDM 的效果不好