- https://yj7082126.github.io/graspdiffusion/
- https://openaccess.thecvf.com/content/WACV2026/html/Kwon_GraspDiffusion_Synthesizing_Realistic_Whole-body_Hand-Object_Interaction_WACV_2026_paper.html
- WACV 2026; Cited by 9
- Patrick Kwon; University of Central Florida
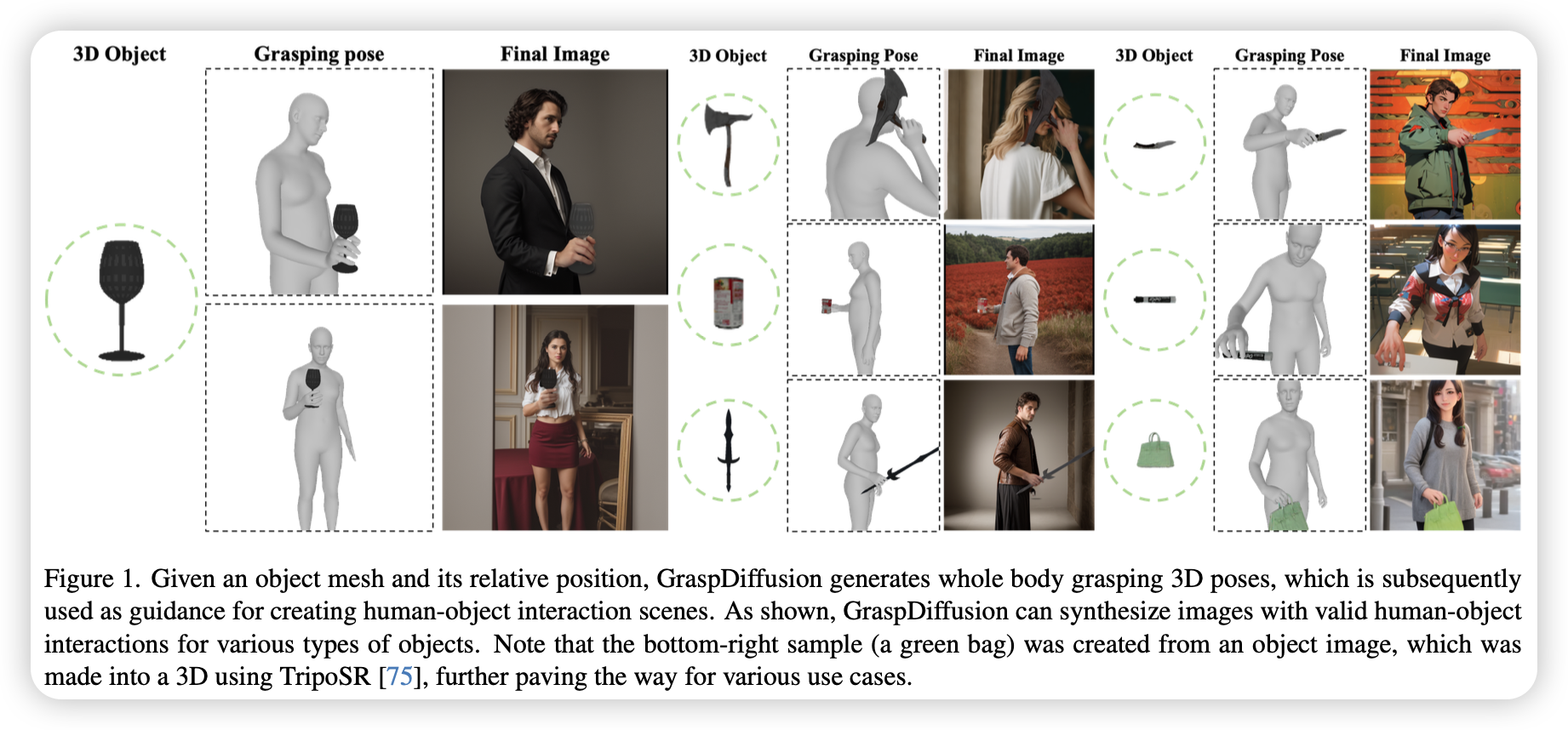
Introduction
Background
近期的生成式模型能够合成高质量的图像,但往往无法准确生成人类用手与物体互动的画面,这主要由于手部在完整人体图像中仅占边缘区域,但其结构复杂,模型很难理解并合成H(and)OI行为。
Related Work
- 有研究将图像修复技术应用于手部区域的优化,但仅聚焦于手部不与其他物体发生交互的场景,或者受相机视角限制且需要预先掌握场景上下文
- Affordance Diffusion和HOI Diffusion借助Affordance能表征人手与物体之间明确的物理接触关系,但无法体现人体空间层面的非接触关系
- ControlNet和T2I-Adapter使用二维人体关键点骨架和深度图,给扩散模型提供额外的细粒度空间条件
- HOI Diffusion可以从合成的抓取姿态生成图像,但视角以手部为中心;Han Diffuser在图像生成中注入手部嵌入向量以生成逼真手部
- 大多数HOI数据集存在可扩展性和变异性问题。尤其是彩色数据集;DexYCB等仅记录于第一人称,未包含人体和空间非接触关系;BEHAVE的图像质量和运动传感器使得内容难以用作真实的图像数据集?
Contribution
- 首个基于给定物体信息生成高质量HOI图像的方法,能够以物理合理的方式呈现显式和隐式交互,相比SOTA有显著提升
- 流程分为两个阶段,第一阶段生成逼真的交互姿态,提供丰富的三维先验信息,第二阶段利用先验,生成高质量的图像
- 设计了一套标注流程,基于现有2D图像交互数据集生成了用于训练的“图像-3D标注”的HOI数据集
- 可基于单张物体图像生成HOI图像,并支持多种艺术风格
Method
0. Definition
- 输入:
- 3D物体网格及其相对人体位置(网格可由一张图像生成)
- 抓取手标识(最后还是右手)和文本提示
- 输出:先生成全身抓取的姿态,然后指导生成2D人物交互图像
- 手部模型:MANO
- 双手姿势 $\theta_h \in R^{15 \times 3}$
- 手腕平移 $t_h \in R^3$ 和全局方向 $R_h \in R^3$
- 全身模型:SMPL-X
- 全身姿态 $\theta_b \in R^{21 \times 3}$
- 双手姿势 $\theta_h$
- 根平移 $t_b \in R^3$
- 全局方向 $R_b \in R^3$
1. Full-Body Grasping
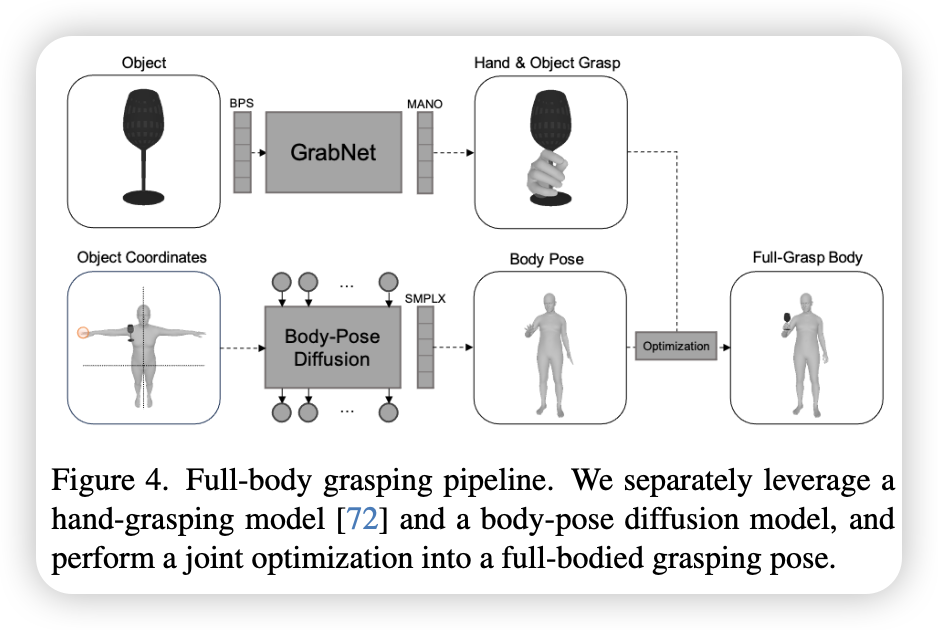
- 输入:一3D物体的网格以及它相对人体躯干(骨盆为原点)的空间位置
- 输出:一物理合理、姿态逼真的3D全身抓取姿势(联合优化的SMPL-X和MANO模型)
- 手部抓取生成 将物体的BPS(基点集)编码输入一预训练的cVAE:GrabNet,输出MANO手部模型的参数。其包含两套权重,用户可指定抓取的是左手还是右手。 BPS和GrabNet结合能生成准确的接触关系并泛化到各种物体。
- 身体姿态生成 使用一条件扩散模型生成SMPL-X参数$x \in R^{132}$(21非手关节+1根关节的6DOF),条件$c = [t{obj}, c{left}, c{right}] \in R^5$ 包括物体相对位置、左右手是否接触($c{left}, c_{right} \in {0,1}$)。 该模块侧重于表达人体和物体之间的空间关系,与物体具体形状无关,因此不关注生成的手部抓取姿态
- 联合对齐与优化 选择固定GrabNet生成的手指关节弯曲姿态以保留完美的抓取形态,同时将手腕对齐到身体上,具体通过最小化MANO和SMPL-X两组手掌对应顶点:$\mathcal{V}{h}^{p}$和$\mathcal{V}{b}^{p}$之间的$L1$距离,来优化手部的旋转$R_h$和位移$th$: $E(R{h},t{h})=\frac{1}{|\mathcal{V}{h}^{p}|}\sum{i=1}^{|\mathcal{V}{h}^{p}|}d{vv}(\mathcal{V}{h{i}}^{p},\mathcal{V}{b_{i}}^{p})$ 利用优化后的相对变换$(R_h, t_h)$将3D物体网格无缝变换到全身统一的坐标系中,生成人、手、物体三者融合的3D全身抓取姿态。
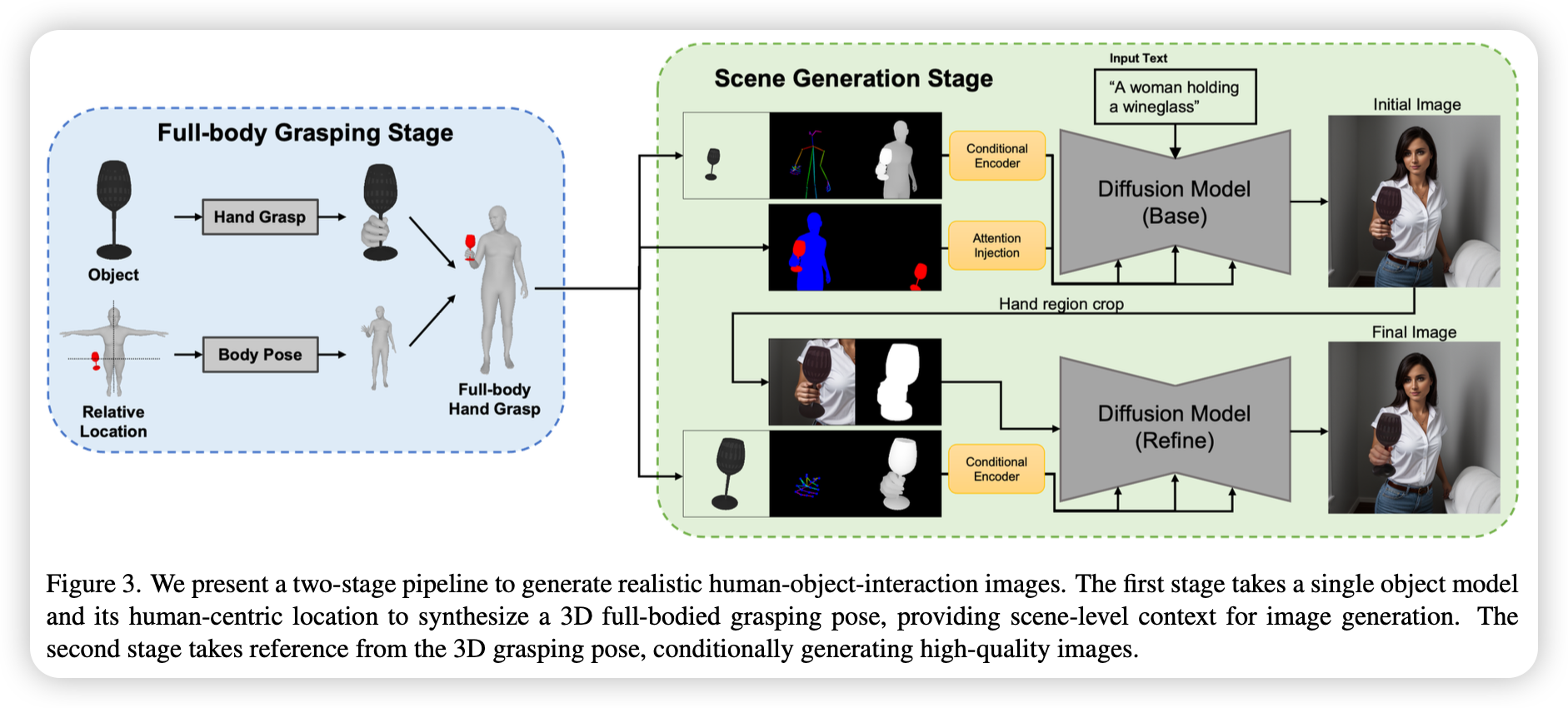
2. Scene Generation
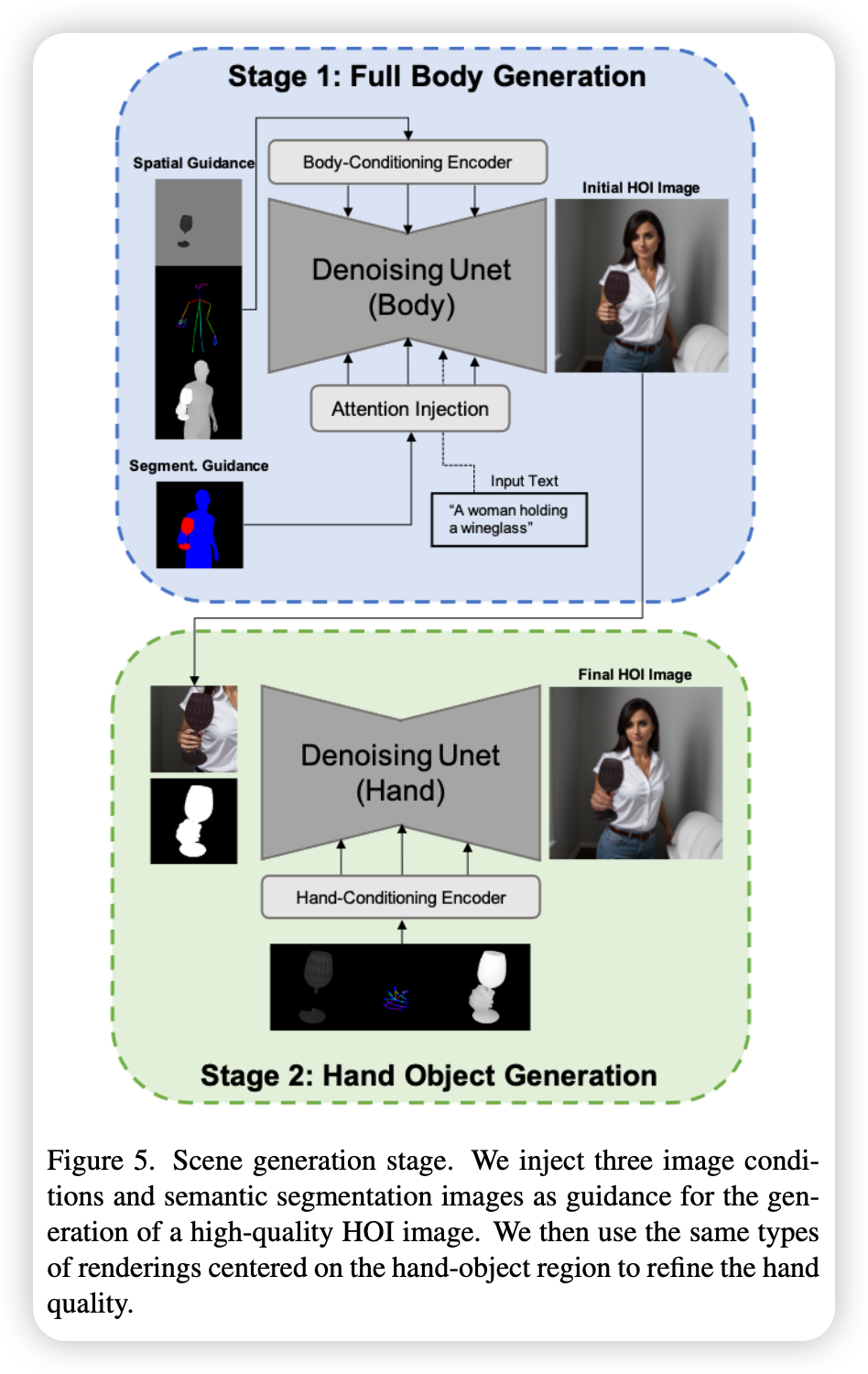
由上面生成的全身3D姿态,先预提取多个空间条件作为最终图像生成的预训练的基础扩散模型(Stable Diffusion)的条件:
- 人体骨架投影$s^i$:SMPL-X的身体和手部关节的2D骨架图,确保生成的人体比例正确
- 联合深度图$d^i$:人体和物体的深度图(黑白灰渐变图),用于给模型提供强烈的3D前后遮挡关系
- 带环境光照的遮挡物体图$o^i$:仅渲染未被遮挡的物体本身,用于保留物体的材质、外观和颜色
三个特征图通过CoAdapter进行特征提取,然后按一定权重相加作为条件注入到基础扩散模型中:$Fc = \sum{k \in {s, d, o }} \omegak \mathcal{F}{AD}^k(k^i)$
- 输入:文本提示和3D空间条件图
- 输出:2D Grasp图像
在训练过程中,冻结基础扩散模型的参数,仅优化条件适配器,从而降低模型收敛到数据集风格的风险。这使得在推理阶段可以通过应用LoRA或者微调后的Stable Diffusion,来控制图像风格。
为了针对手部-物体进行细化,在生成的全局图像中,以手和物体为中心裁剪出一块局部区域,针对这个区域再提取局部的骨架、深度图、物体图,送入手部细化适配器(结构与身体条件适配器类似,但单独训练),使得手部纹理与物体边缘更加自然。
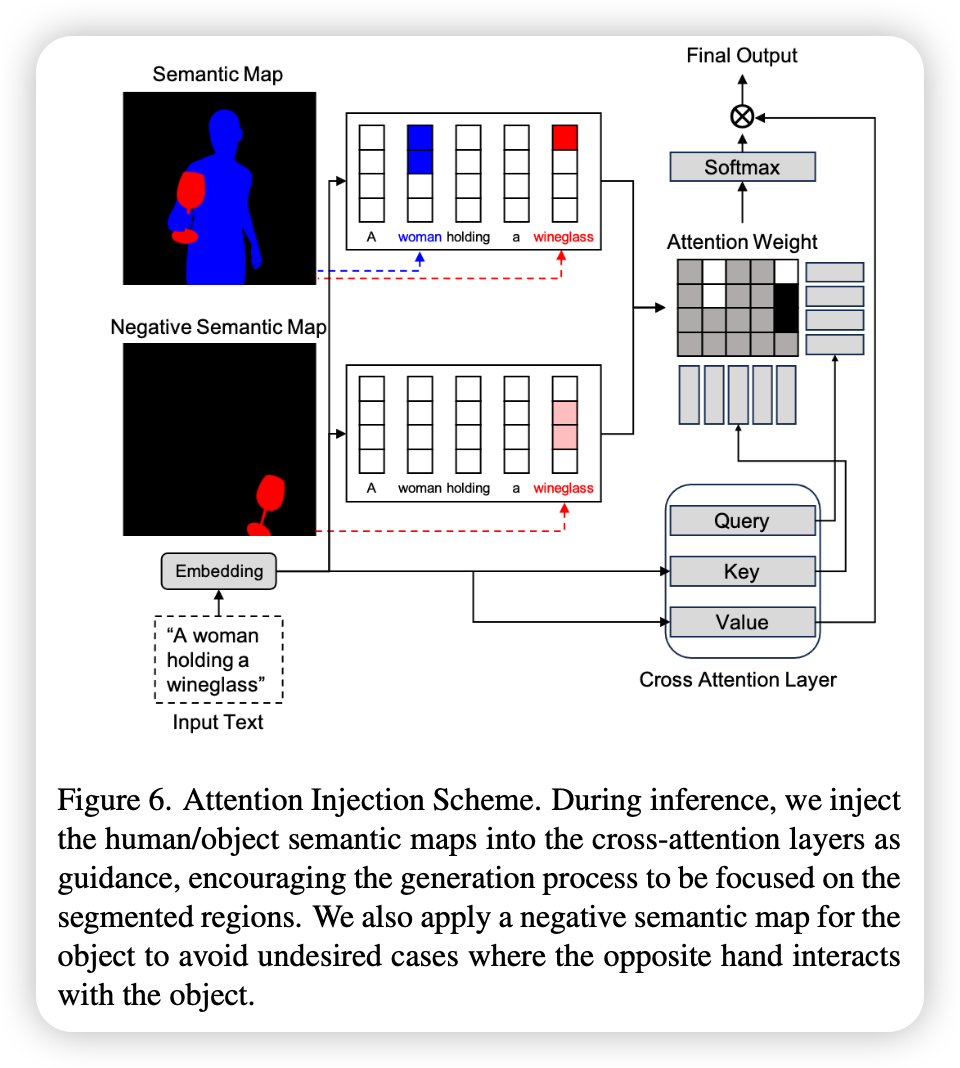
为了解决交互可能发生在预期区域以外位置的情况,提出了一种干预交叉注意力层的方法:从3D模型中渲染出人体和目标物体的二维语义分割色块,在模型生成时,强制代表“人”和“物体”的文本token只能去关注图像中对应的色块区域;为了防止用另一只手去拿东西,先渲染一张“用错手去拿物体”的伪分割图,在注意力计算矩阵中,直接减去这个负向区域。
Experiment
Dataset
为弥补“高质量2D图像+对应3D姿态和物体”的配对数据,利用来自HICO-DET和VCOCO的人物交互图像来构建伪3D交互数据集。
- BLIP-2识别图片中的人交互的物体类型; Grounding-DINO框出物体并作分割
- 深度估计模型提取深度图,骨架估计模型提取2D骨架; HybrIK提取人的3D SMPL-X 姿态
- ACR模型估计手的3D MANO参数
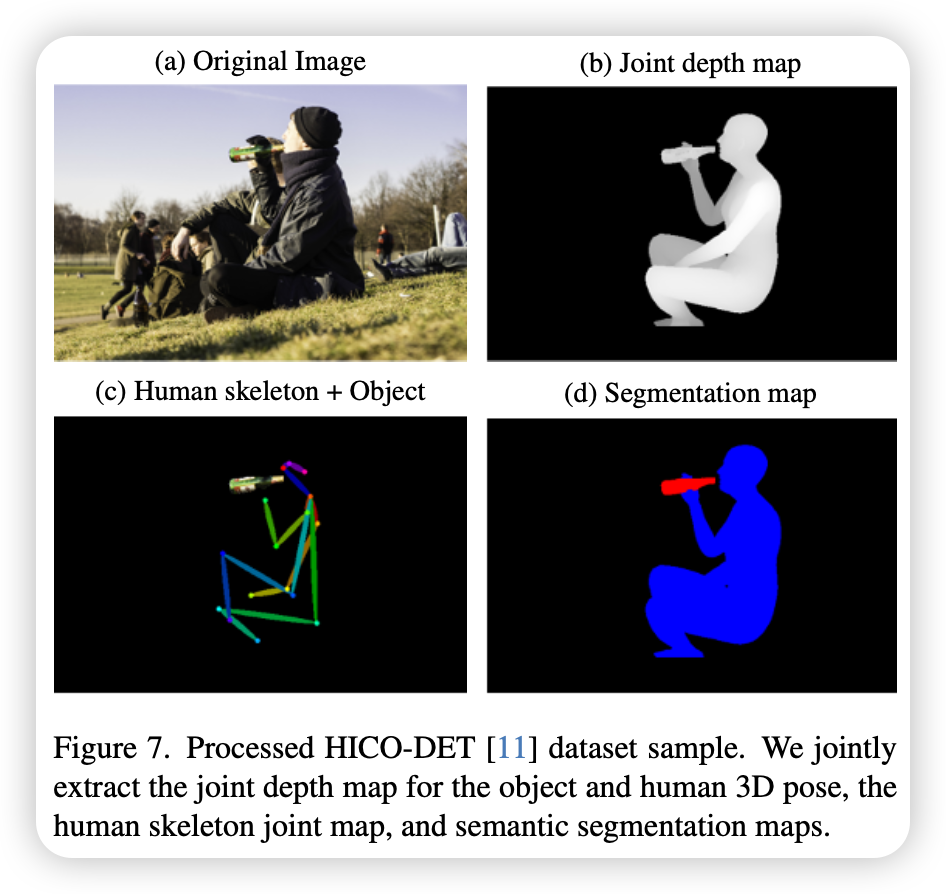
对于手部优化模块,处理DexYCB和RHD数据集,并预处理HICO-DET的子集(裁剪在手-物边界框上)以拓宽手-物交互分布。
在GRAB数据集上训练全身抓取扩散模型;用上述数据集以Stable Diffusion v1.5作为基础模型并冻结参数训练条件模块。
Metric
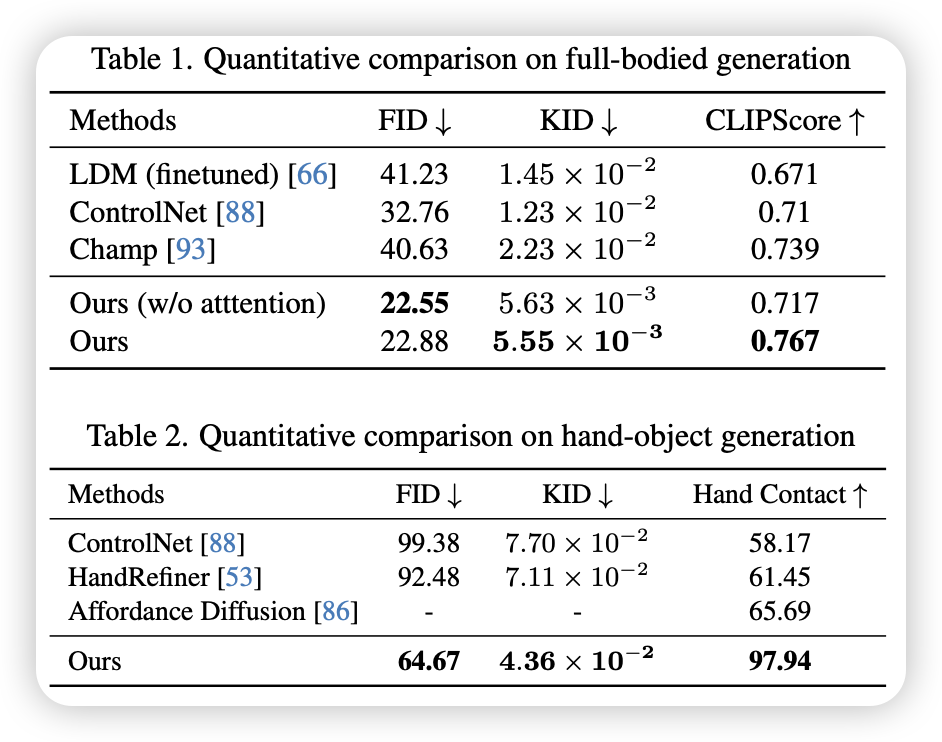
- 全身生成质量:FID、KID、CLIPScore(图文匹配度)
- 手部抓取质量:FID、KID、手部接触
- 3D姿势评估:接触率、姿态错误率、Displacement
- 其他:用户喜好评估
Result
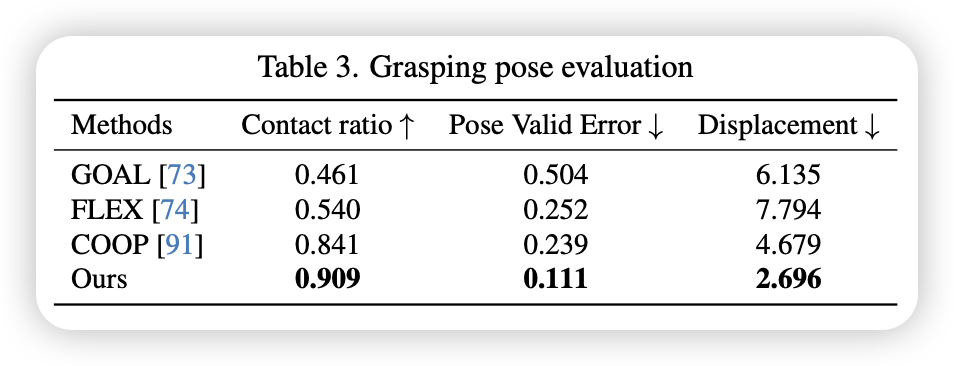
为了评估针对不同物体和位置抓取姿势的合理性,构建了一个分布在远离训练集原始范围的看不见的物体的测试集。 GraspDiffusion拥有最好的效果,即使物体被放在了不可思议的距离,也能生成合理的动作。
Ablation
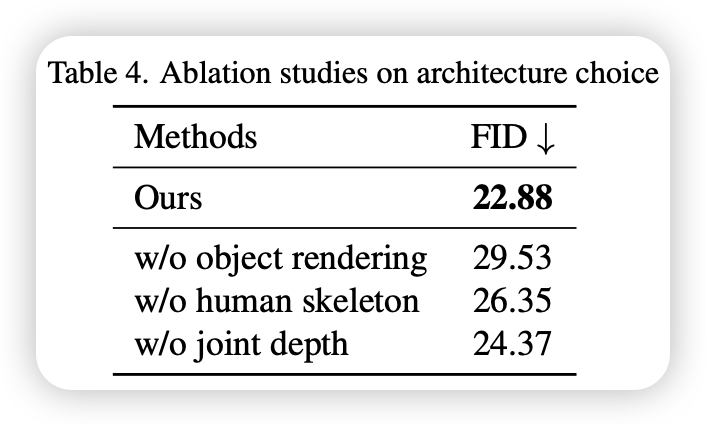
- 三个控制条件缺一个,FID都会下降
- 去掉注意力注入FID会略好,但CLIPScore会变低